[20:07] <@Gynvael> najpierw ogloszenie duszpasterskie
[20:07] <@Gynvael> z uwagi na prosbe sluchaczy dwa wyklady zostaly PRZESUNIETE
[20:08] <@Gynvael> Jest to wyklad j00ru "Cracking - podstawy" ktory odbedzie sie JUTRO. Zostal przesuniety z godziny 20:00 na godzine 17:00
[20:08] <@Gynvael> Drugi przesuniety wyklad to wyklad unknowa "Budowa stron WWW w oparciu o kaskadowe arkusze stylów" ktory odbedzie sie w SOBOTE. Zostal przesuniety z godziny 20 na godzine 18:30
[20:09] <@Gynvael> jeszcze jest niepewna sytuacja wykladu srodowego
[20:09] <@Gynvael> MOZE sie zdazyc ze bedzie rowniez przesuniety na 18:30
[20:09] <@Gynvael> Bedziemy o tym informowac
[20:09] <@Gynvael> ok
[20:09] <@Gynvael> tyle ogloszen
[20:09] <@Gynvael> przypominam ze mozna komentowac poprzedni wyklad na naszym forum http://forum.wyklady.net/index.php?topic=18.0
[20:10] <@Gynvael> Witam na drugim dzisiejszym wykladzie
[20:10] <@Gynvael> rowniez prowadzonym przezemnie ;p
[20:10] <@Gynvael> tematem wykladu sa podstawowe algorytmy kompresji danych, z implementacja w C++
[20:10] <@Gynvael> dzisiaj glownie bedzie teoria, troche kodu tez mignie
[20:11] <@Gynvael> ale niestety z uwagi na to ze sesja egzaminacyjna mi sie przedluzyla, nie ze wszystkim zdazylem ;<
[20:11] <@Gynvael> w zwiazku z czym bedzie jeszcze jeden wyklad, na ktorym bedzie glownie omawianie implementacji
[20:11] <@Gynvael> ok
[20:11] <@Gynvael> jedziemy
[20:11] <@Gynvael> celem kompresji jak wiadomo jest zmniejszenie obietosci danych
[20:11] <@Gynvael> ale w taki sposob, zeby mozna odzyskac je w orginalnej postaci
[20:12] <@Gynvael> kompresja jest szeroko wykorzystywana, w sumie wszedzie
[20:12] <@Gynvael> od takich powszechnie znanych rzeczy
[20:12] <@Gynvael> jak np kompresja plikow (.zip, .rar, .bz2, .gz, etc)
[20:13] <@Gynvael> kompresja grafiki (.gif, .jpg, .png, .tga, .bmp)
[20:13] <@Gynvael> kompresja muzyki (.mp3, .wav, .ogg, .flac)
[20:13] <@Gynvael> poprzez kompresje plikow wykonywalnych (np UPX i projekt windowsa 95 zajmujacego 4mb)
[20:14] <@Gynvael> kompresje filmow (jak podpowiada KosiarZ) ;>
[20:14] <@Gynvael> do kompresji wykozystywanej w transferze danych, np protokol http (ten od stron www) umozliwia przesylanie spakowanych stron (gzip)
[20:15] <@Gynvael> czy chodzby samej kompresji stosowanej np w modemach
[20:15] <@Gynvael> ad pytania na priv: projekt 4mb windy zostal zdjety z sieci bo sie Microsoft burzyl ;p
[20:16] <@Gynvael> w sumie nawet systemy plikow (patrz np drivespace i double space pod dosem) moga byc kompresowane ;>
[20:16] <@Gynvael> wszedzie kompresja ;>
[20:16] <@Gynvael> ok ;>
[20:16] <@Gynvael> kompresja dzieli sie na dwa rodzaje
[20:16] <@Gynvael> 1) bezstratna
[20:16] <@Gynvael> 2) stratna
[20:17] <@Gynvael> bezstratna kompresja polega na takim skompresowaniu czegos, zeby mozna potem to rozkompresowac tak zeby dane byly zgodne w 100% z oryginalem
[20:17] <@Gynvael> w przypadku bezstratnej ten warunek nie jest wymagany
[20:17] <@Gynvael> wazne zeby dane byly podobne ;>
[20:18] <@Gynvael> *stratnej
[20:18] <@Gynvael> ;p
[20:18] <@Gynvael> ok ;>
[20:18] <@Gynvael> teraz jak to uzyskac ?
[20:18] <@Gynvael> postaram sie przedstawic pare algorytmow ;>
[20:18] <@Gynvael> Najprostszym moim zdaniem algorytmem kompresji, ktory cos tam daje, jest RLE
[20:18] <@Gynvael> Run length encoding
[20:18] <@Gynvael> czyli kodowanie dlugosci
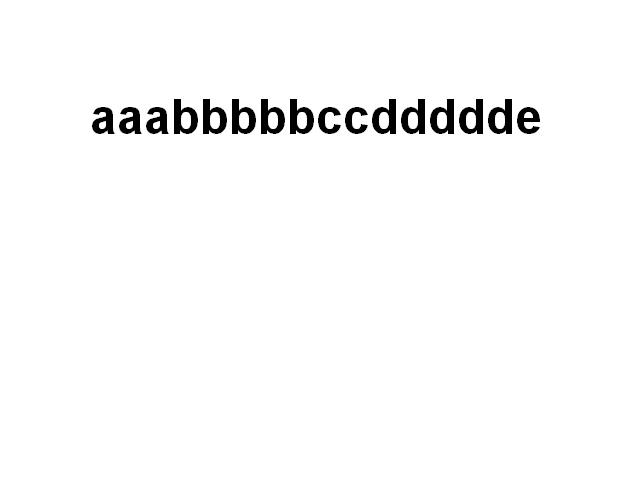
[20:19] <@Gynvael> wezmy sobie przykladowy ciag
[20:19] <@Gynvael> "aaabbbbbccddddde"
[20:19] <@Gynvael> o taki
[20:19] <@Gynvael> zastanowmy sie jak bysmy zapytali kolege
[20:19] <@Gynvael> co tam pisze
[20:19] <@Gynvael> to co by powiedzial
[20:19] <@Gynvael> (ew kolezanke ;>)
[20:20] <@Gynvael> czy by powiedzial "aaabbbbbc.." ?
[20:20] <@Gynvael> a moze by powiedzial "trzy a, potem 5 b, dwa c" etc
[20:20] <@Gynvael> czesc osob pewnie by uzyla tego drugiego sposoby
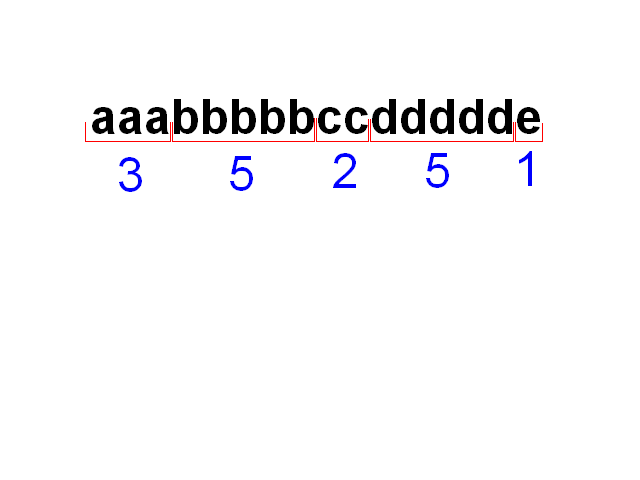
[20:21] <@Gynvael> zastosujmy ten sposob w kompresji
[20:21] <@Gynvael> *do kompresji
[20:21] <@Gynvael> umowmy sie ze oryginalny ciag
[20:21] <@Gynvael> zapiszemy jako
[20:22] <@Gynvael> ciag par, liczba - ilosc powtorzen, znak

[20:22] <@Gynvael> mielismy 16 znakow oryginalnego ciagu "aaabbbbbccddddde"
[20:22] <@Gynvael> ciag wyjsciowy wyszedl nam "3a5b2c5d1e", czyli 10 znakow
[20:23] <@Gynvael> czyli 62,5% kompresji (10/16 * 100%)
[20:23] <@Gynvael> calkiem niezly wynik
[20:23] <@Gynvael> -=202402=- <@crgh0st> ale imho jesli beda same pojedyncze literki to to wydluzymy anizeli skrocimy ;>
[20:23] <@Gynvael> ano wlasnie ;>
[20:23] <@Gynvael> to jest wada tego sposobu RLE
[20:24] <@Gynvael> wezmy np ciag
[20:24] <@Gynvael> "abcabcabcabcaaaaa"
[20:24] <@Gynvael> jak widac
[20:24] <@Gynvael> tutaj ciag wyjsciowy wyszedl by
[20:24] <@Gynvael> "1a1b1c1a1b1c1a1b1c1a1b1c5a"
[20:24] <@Gynvael> czyli dluuuuuzszy niz oryginalny
[20:25] <@Gynvael> jak slusznie ved na privie zauwazyl
[20:25] <@Gynvael> dla kazdego algorytmu
[20:25] <@Gynvael> znajdzie sie jakis 'wredny' ciag danych
[20:25] <@Gynvael> ktory spowoduje ze po prostu algorytm nie bedzie dzialal
[20:25] <@Gynvael> <@drk_tg> ale jezeli znak wystepuje 1 raz to mozemy pominac liczbe wystapien
[20:25] <@Gynvael> i tak wlasnie wyglada drugi sposob
[20:25] <@Gynvael> kompresji RLE
[20:26] <@Gynvael> wezmy jakis znak
[20:26] <@Gynvael> ktory nei wystepuje w danych
[20:26] <@Gynvael> np literka Z
[20:26] <@Gynvael> i piszmy normalnie dane
[20:26] <@Gynvael> ale
[20:26] <@Gynvael> gdy stwierdzimy ze jest duuuuuuuzo powtoorzen
[20:26] <@Gynvael> to piszemy znacznik - Z
[20:26] <@Gynvael> po czym liczbe wystapien i znak
[20:27] <@Gynvael> 'duzo powtorzen' dla nas to wiecej niz 3
[20:27] <@Gynvael> poniewaz 3 znaki zajmie zaznaczenie ilosci powtorzen
[20:27] <@Gynvael> np
[20:27] <@Gynvael> "ababaaaaaaaaaa"
[20:27] <@Gynvael> "ababZ9a"

[20:28] <@Gynvael> wrocmy do naszego przykladowego ciagu
[20:28] <@Gynvael> trzeba zauwazyc
[20:28] <@Gynvael> ze ciag wyszedl DLUZSZY
[20:28] <@Gynvael> niz ciag skompresowany bez markerow
[20:28] <@Gynvael> ale to tylko przypadek, takie dane ;>
[20:28] <@Gynvael> ten sposob jest odporny stosunkowo na wredne ciagi
[20:28] <@Gynvael> tzn ratio nigdy nie przekroczy 100% (moze byc mniejsze, ale nie wieksze)
[20:28] <@Gynvael> ok
[20:29] <@Gynvael> przetestujmy ten sposob w praktyce
[20:29] <@Gynvael> a
[20:29] <@Gynvael> jeszcze chwila
[20:29] <@Gynvael> jesli wszystkie znaki wystepuja
[20:29] <@Gynvael> to mozemy wybrac marker ktory sklada sie z dwoch znakow
[20:30] <@Gynvael> a jesli wystepuja wszystkie kombinacje dwuznakowe (tych kombinacji jest 65tys)
[20:30] <@Gynvael> to wezmy 3 znaki
[20:30] <@Gynvael> a jesli... to 4 ;>
[20:30] <@Gynvael> etc ;>
[20:30] <@Gynvael> 4ro znakowych kombinacji jest ponad 4mln
[20:31] <@Gynvael> wiec na pewno jakas kombinacja sie znajdzie
[20:31] <@Gynvael> ew mozna zastosowac escape'owanie ;>
[20:31] <@Gynvael> etc
[20:31] <@Gynvael> mozliwosci jest duzo ;>
[20:31] <@Gynvael> druga sprawa
[20:31] <@Gynvael> to dekompresja
[20:31] <@Gynvael> chyba kazdy wie jak to zalatwic nie ? ;>
[20:31] <@Gynvael> to bedzie zadanie domowe hehe ;>
[20:32] <@Gynvael> ok
[20:32] <@Gynvael> rzucmy okiem na jakies prawdziwe dane
[20:32] <@Gynvael> http://furio.vexillium.org/~wyklady/pack/kompresja.zip
[20:32] <@Gynvael> tam znajduje sie implementacja KOMPRESJI RLE z i bez markerow (4ro bajtowy marker)
[20:32] <@Gynvael> w C++
[20:32] <@Gynvael> oraz zestaw 7 testow
[20:32] <@Gynvael> staralem sie wybrac roznorodne testy
[20:32] <@Gynvael> tak wiec:
[20:33] <@Gynvael> test1.in to jest 1000 liter, ABCD, wystepujacych w roznej ilosci, czyli marzenie kazdego algorytmu kompresji ;>
[20:33] <@Gynvael> test2.in to log z wykladu (9wiatego) z C ;>
[20:33] <@Gynvael> test3.in to EXE, hello world skompilowany gcc hello.c -g
[20:34] <@Gynvael> nastepne 4ry testy to bitmapy
[20:34] <@Gynvael> test4 - BMP 256x256x24, prostokat, kolo, etc
[20:34] <@Gynvael> test5 - BMP 256x256x24, fotka pszczoly
[20:34] <@Gynvael> test6 - BMP 256x256x8, prostokat, kolo, etc
[20:34] <@Gynvael> test7 - BMP 256x256x8, fotka pszczoly
[20:34] <@Gynvael> test4 i test6 sa proste, tj nie ma zadnego cieniowanie etc, tylko 3 kolorki
[20:34] <@Gynvael> mozecie sobie pozmieniac rozszerzenie na BMP i obejrzec
[20:34] <@Gynvael> natomiast test5 i test7 to fotografia pszczoly z mojego ogrodu, ktora mnie prosila zeby pojawic sie na wykladzie z kompresji ;p
[20:35] <@fnx> re
[20:35] <@Gynvael> fnx: re, csii ;>
[20:35] <@fnx> ups
[20:35] <@Gynvael> hm
[20:35] <@Gynvael> wyglada na to ze makefile nie zrobilem
[20:35] <@Gynvael> niewazne
[20:35] <@Gynvael> kompilacja wyglada nastepujaco
[20:36] <@Gynvael> kod po krootce za chwile omowie
[20:36] <@Gynvael> 20:05:27 >g++ FileContent.cpp RunLength.cpp test_RunLengthMarker.cpp -o testM
|
[20:36] <@Gynvael> testP kompresuje normalnie, parami, bez znacznika
[20:37] <@Gynvael> a testM kompresuje ze znacznikiem ;>
[20:37] <@Gynvael> ok
[20:37] <@Gynvael> wiec odpalmy krotki tescik
[20:38] <@Gynvael> 20:38:16 >for %i in (*.in) do @testP %i %i.out
|
[20:39] <@Gynvael> dostalem priva ze kod sie nie kompiluje na VC++
[20:39] <@Gynvael> hmm nie testowalem szczerze mowiac, jak mowilem, nie ze wszystkim zdazylem
[20:39] <@Gynvael> postaram sie na druga czesc poprawic ten kod zeby sie wszedzie kompilowal
[20:40] <@Gynvael> ok
[20:40] <@Gynvael> rzucmy okiem na wyniki ktore wkleilem
[20:40] <@Gynvael> syntetyczny test 1000 literek sie ladnie skompresowal
[20:40] <@Gynvael> do 214 bajtow
[20:41] <@Gynvael> czyli ratio wynioslo 21.4%
[20:41] <@Gynvael> lepszy wynik uzyskal jedynie obrazek figur geometrycznych w 8 bitach
[20:41] <@Gynvael> 3,9%
[20:41] <@Gynvael> z 66kb do 2,5kb
[20:42] <@Gynvael> w 24 bitach wypadla kompresja gorzej
[20:42] <@Gynvael> 65% ratio
[20:42] <@Gynvael> natomiast reszta testow poszla fatalnie
[20:43] <@Gynvael> wszystkie wynikowe pliki wieksze niz oryginalny!
[20:43] <@Gynvael> wyglada na to ze w danych binarnych, i w logach z irca, czesto zdarza sie "wredny przypadek" danych
[20:43] <@Gynvael> zobaczmy wiec jak sobie radzi rozwiazanie z markerem
[20:44] <@Gynvael> 20:38:52 >for %i in (*.in) do @testM %i %i.out
|
[20:44] <@Gynvael> natomiast test pierwszy poszedl slabiej
[20:44] <@Gynvael> test przedostatni tez
[20:45] <@Gynvael> RLE (bez markera): 1000 -> 214 ( 21.4%)
[20:45] <@Gynvael> RLE (marker): 1000 -> 472 ( 47.2%)
[20:45] <@Gynvael> i
[20:45] <@Gynvael> RLE (bez markera): 66614 -> 2608 ( 3.9%)
[20:45] <@Gynvael> RLE (marker): 66614 -> 4679 ( 7.0%)
[20:45] <@Gynvael> natomiast reszta testow poszla duzo lepiej
[20:45] <@Gynvael> log z irca i fotografia pszczoly w 24bit nie skompresowaly sie wogole
[20:45] <@Gynvael> czego mozna bylo sie spodziewac
[20:46] <@Gynvael> natomiast reszta tak
[20:46] <@Gynvael> plik wykonywalny ktory bez markera sie rozrosl
[20:46] <@Gynvael> RLE (bez markera): 19235 -> 22644 (117.7%)
[20:46] <@Gynvael> sie skompresowal
[20:46] <@Gynvael> RLE (marker): 19235 -> 15477 ( 80.5%)
[20:46] <@Gynvael> rowniez foto pszczoly w 8 bitach
[20:46] <@Gynvael> RLE (bez markera): 66614 -> 95310 (143.1%)
[20:46] <@Gynvael> RLE (marker): 66614 -> 66024 ( 99.1%)
[20:47] <@Gynvael> zostalo skompresowane
[20:47] <@Gynvael> hm
[20:47] <@Gynvael> jak juz jestem przy plikach wykonywalnych i ich kompresji
[20:47] <@Gynvael> zdarza sie czesto, np w UPX (filtry UPXa)
[20:48] <@Gynvael> ze przed kompresja algorytm wyszukuje instrukcji skoku w pakowanym kodzie
[20:48] <@Gynvael> (przypominam ze UPX pakuje pliki wykonywalne, tak aby dalej mogly sie wykonywac ;>)
[20:48] <@Gynvael> skokow typu
[20:48] <@Gynvael> call adres
[20:48] <@Gynvael> jmp long adres
[20:48] <@Gynvael> i zamienia kolejnosc bajtow w ich parametrach
[20:48] <@Gynvael> z little-endian, bo big-endian
[20:49] <@Gynvael> sprawia to ze kod sie lepiej kompresuje ;>
[20:49] <@Gynvael> zagadka dla was, dlaczego ;>
[20:49] <@Gynvael> a teraz jedziemy dalej
[20:49] <@Gynvael> omowmy kawalek kodu tych programow co wam wyslalem
[20:49] <@Gynvael> test_RunLengthMarker.cpp
[20:50] <@Gynvael> ten plik jest odpowiedzialny za wczytanie danych z plikow
[20:50] <@Gynvael> i skompresowanie ich
[20:50] <@Gynvael> oraz zapisanie
[20:50] <@Gynvael> ma raczej prosta konstrukcje
[20:50] <@Gynvael> if(!GetFileContent(argv[1], InBuffer, InSize))
[20:50] <@Gynvael> czyli odczyt
[20:50] <@Gynvael> if(!GetFileContent(argv[1], InBuffer, InSize))
[20:50] <@Gynvael> eh
[20:50] <@Gynvael> Ratio = RunLengthEncMarker(InBuffer, InSize, OutBuffer, OutSize);
[20:50] <@Gynvael> czyli kompresja
[20:50] <@Gynvael> i
[20:50] <@Gynvael> PutFileContent(argv[2], OutBuffer, OutSize);
[20:51] <@Gynvael> czyli zapis
[20:51] <@Gynvael> funkcje GetFileContent i PutFileContent sa oprogramowane w FileContent.cpp a zadeklarowane w FileContent.h
[20:51] <@Gynvael> i ich glownym celem jest wczytanie zawartosci pliku do tablicy
[20:51] <@Gynvael> i zapisanie tejze tablicy do pliku
[20:52] <@Gynvael> sa to raczej proste funkcyjki wiec nei bede ich omawiac
[20:52] <@Gynvael> rzucmy okiem natomiast na plik
[20:52] <@Gynvael> RunLength.cpp
[20:52] <@Gynvael> sa tam dwie procki
[20:52] <@Gynvael> float
[20:52] <@Gynvael> RunLengthEncMarker(const unsigned char *InData, size_t InLength, unsigned char *OutData, size_t &OutLength)
[20:52] <@Gynvael> oraz
[20:52] <@Gynvael> float
[20:52] <@Gynvael> RunLengthEncPair (const unsigned char *InData, size_t InLength, unsigned char *OutData, size_t &OutLength)
[20:52] <@Gynvael> jak sie latwo domyslic, jedna kompresuje z markerem
[20:52] <@Gynvael> a druga bez
[20:52] <@Gynvael> funckje przyjmuja:
[20:53] <@Gynvael> InData - dane wejsciowe
[20:53] <@Gynvael> InLength - dlugosc tych danych
[20:53] <@Gynvael> OutData - buffor wyjsciowy
[20:53] <@Gynvael> i OutLength - czyli wielkosc buforu wyjsciowego przy wejsciu, i ilosc bajtow wykorzystanych przy wyjsciu
[20:54] <@Gynvael> przeanalizujmy funkcje
[20:54] <@Gynvael> a
[20:54] <@Gynvael> btw te funkcje zwracaja ratio
[20:54] <@Gynvael> przeanalizujmy funkcje RunLengthEncPair
[20:54] <@Gynvael> najpierw jest troche deklaracji etc
[20:54] <@Gynvael> unsigned char Byte;
[20:54] <@Gynvael> unsigned long Repeat;
[20:54] <@Gynvael> unsigned char *OutPtr = OutData;
[20:54] <@Gynvael> const unsigned char *InPtr = InData;
[20:54] <@Gynvael> unsigned char *OutEnd = OutData + (OutLength / 2) * 2;
[20:54] <@Gynvael> const unsigned char *InEnd = InData + InLength;
[20:54] <@Gynvael> OutPtr to pointer na poczatek buforu wyjsciowego
[20:55] <@Gynvael> InPtr to pointer na dane wejsciowe
[20:55] <@Gynvael> OutEnd to pointer na koniec buforu (z upewnieniem sie ze bufor ma parzysta wielkosc)
[20:55] <@Gynvael> a InEnd to pointer na koniec buforu wejsciowego
[20:55] <@Gynvael> potem jest wlona petla
[20:55] <@Gynvael> while(InPtr < InEnd && OutPtr < OutEnd)
[20:55] <@Gynvael> {
[20:55] <@Gynvael> Byte = *InPtr++;
[20:55] <@Gynvael> Repeat = 1;
[20:55] <@Gynvael> while(*InPtr == Byte && Repeat < 0xff && InPtr < InEnd) InPtr++, Repeat++;
[20:55] <@Gynvael> OutPtr[0] = Byte;
[20:55] <@Gynvael> OutPtr[1] = (unsigned char)Repeat;
[20:55] <@Gynvael> OutPtr += 2;
[20:55] <@Gynvael> }
[20:56] <@Gynvael> czyli
[20:56] <@Gynvael> 1. do poki beda dane i bedzie gdzie je zapisac
[20:56] <@Gynvael> 2. pobierz bajt
[20:56] <@Gynvael> 3. zapisz sobie ze sie powtorzy 1 raz
[20:56] <@Gynvael> 4. sprawdz ile razy bajt sie powtarze (uwazajac na koniec bufora)
[20:56] <@Gynvael> 5. zapisz bajt
[20:56] <@Gynvael> 6. zapisz ilosc potworzen
[20:56] <@Gynvael> 7. przesun pointer zapisu o dwa do przodu
[20:57] <@Gynvael> i skocz do punktu 1
[20:57] <@Gynvael> chcial bym odrazu zauwazyc ze tutaj nie zapisujemy ilosc powtorzen + znak
[20:57] <@Gynvael> tylko znak + ilosc powtorzen
[20:57] <@Gynvael> czyli odwrotnie niz w przykladach teoretycznych
[20:58] <@Gynvael> petelka jest raczej prosta jak mowilem
[20:58] <@Gynvael> rzucmy okiem na RunLengthEncMarker
[20:58] <@Gynvael> czyli kompresje z markerem
[20:58] <@Gynvael> po inicjalizacji jest tam wybieranie markera
[20:58] <@Gynvael> wybieranie jest tutaj raczej dosc glupio zrobione
[20:58] <@Gynvael> poniewaz wybieram z gory marker
[20:58] <@Gynvael> unsigned long Marker = 0x1337BABE;
[20:59] <@Gynvael> a nastepnie sprawdzam czy taki ciag wystepuje w danych wejsciowych
[20:59] <@Gynvael> jezeli wystapi
[20:59] <@Gynvael> to xoruje ten marker z losowa liczba
[20:59] <@Gynvael> i testuje znowu
[20:59] <@Gynvael> jak wybierac taki marker to temat na osobny wyklad ;>
[20:59] <@Gynvael> podpowiem tylko ze imho stworzenie histogramu i wybranie 4rech najrzadziej powtarzajacych sie elementow dalo by niezle rezultaty
[21:00] <@Gynvael> po wyborze markera
[21:00] <@Gynvael> jest kompresja
[21:00] <@Gynvael> nowym elementem tutaj jest sprawdzanie czy warto uzyc RLE
[21:00] <@Gynvael> while(*InPtr == Byte && Repeat < 0xff && InPtr < InEnd) InPtr++, Repeat++;
[21:00] <@Gynvael> if(Repeat < sizeof(Marker) + 3 || (size_t)(OutEnd - OutPtr) < sizeof(Marker) + 2)
[21:00] <@Gynvael> {
[21:00] <@Gynvael> while(Repeat-- && OutPtr < OutEnd) *OutPtr++ = Byte;
[21:00] <@Gynvael> }
[21:00] <@Gynvael> else
[21:00] <@Gynvael> {
[21:00] <@Gynvael> *(unsigned long*)OutPtr = Marker;
[21:00] <@Gynvael> OutPtr += sizeof(Marker);
[21:00] <@Gynvael> OutPtr[0] = Byte;
[21:00] <@Gynvael> OutPtr[1] = (unsigned char)Repeat;
[21:00] <@Gynvael> OutPtr += 2;
[21:00] <@Gynvael> }
[21:01] <@Gynvael> czyli
[21:01] <@Gynvael> sprawdz ile razy znak sie powtarza
[21:01] <@Gynvael> po czym sprawdz czy czasem ilosc powtorzen nie jest mniejsza niz miejsce potrzebne na zapisanie markera
[21:01] <@Gynvael> i liczby powtozen
[21:02] <@Gynvael> jesli nie warto uzywac RLE (czyli liczba powtorzen jest mniejsza), to przepisz po prostu te znaki
[21:02] <@Gynvael> while(Repeat-- && OutPtr < OutEnd) *OutPtr++ = Byte;
[21:02] <@Gynvael> a jesli warto
[21:02] <@Gynvael> to spisz to ;>
[21:02] <@Gynvael> standardowe RLE tam jest ;> to co bylo w tej drugiej funkcji
[21:02] <@Gynvael> ok
[21:02] <@Gynvael> tyle jesli chodzi o RLE
[21:02] <@Gynvael> 3 minuty przerwy i przejdziemy do huffmana
[21:02] <@Gynvael> pytania na priv ;>
[21:02] <@Gynvael> odpowiem po przerwie
[21:07] <@Gynvael> dobra
[21:07] <@Gynvael> jedziemy dalej
[21:07] <@Gynvael> teraz czas na troche bardziej zaawansowany algorytm ;>
[21:07] <@Gynvael> jest nim algorytm Huffmana
[21:08] <@Gynvael> jest to algorytm kompresji slownikowej
[21:08] <@Gynvael> czyli trzeba stworzyc jakas tablice translacji
[21:08] <@Gynvael> miedzy danymi oryginalnymi
[21:08] <@Gynvael> a danymi zakodowanymi
[21:08] <@Gynvael> algorytm huffmana opiera sie o prosta zasade
[21:09] <@Gynvael> znaki ktore wystepuja czesto, kodujemy jak najmniejsza liczba BITOW
[21:09] <@Gynvael> a znaki ktore wystepuja rzadko, moga byc kompresowane duza iloscia bitow
[21:10] <@Gynvael> wezmy sobie ciag przykladowy z RLE
[21:10] <@Gynvael> "aaabbbbbccdddde"
[21:10] <@Gynvael> stworzmy histogram
[21:10] <@Gynvael> czyli tablice czestosci wystepowania kazdego znaku
[21:10] <@Gynvael> to akurat jest prosta sprawa
[21:10] <@Gynvael> zazwyczaj w implementacji wyglada to tak:
[21:11] <@Gynvael> unsigned char *dane = jakiesdane;
[21:11] <@Gynvael> int hist[256];
[21:11] <@Gynvael> memset(hist, 0, sizeof(hist));
[21:11] <@Gynvael> int i;
[21:11] <@Gynvael> for(i = 0; i < dlugosc_danych; i++) hist[dane[i]]++;
[21:11] <@Gynvael> ;>
[21:11] <@Gynvael> w naszym przypadku histogram wyglada nastepujaco:
[21:12] <@Gynvael> a - 3
[21:12] <@Gynvael> b - 5
[21:12] <@Gynvael> c - 2
[21:12] <@Gynvael> d - 5
[21:12] <@Gynvael> e - 1
[21:12] <@Gynvael> i teraz
[21:12] <@Gynvael> stworzmy sobie liste-drzewo ;>
[21:12] <@Gynvael> taka dosc ciekawa strukture danych
[21:12] <@Gynvael> ktora ma wskazniki na sasiadow
[21:12] <@Gynvael> znak
[21:12] <@Gynvael> wage (ilosc wystapien znaku)
[21:12] <@Gynvael> i wskazniki na dzieci (lewe i prawe)
[21:13] <@Gynvael> http://furio.vexillium.org/~wyklady/pack/huff01.png
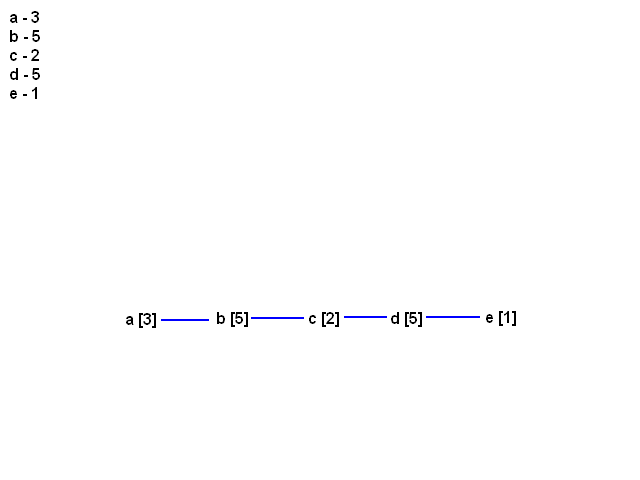
[21:13] <@Gynvael> na poczatku ta lista bedzie wygladac tak
[21:13] <@Gynvael> a nawiasie [] podaje ilosc elementow
[21:13] <@Gynvael> wszelkie polaczenia wskaznikowe ilustruje graficznie
[21:13] <@Gynvael> i teraz przeprowadzamy nastepujace operacje na tej liscie (na liscie, tylko na liscie, nie na drzewie)
[21:14] <@Gynvael> 1) szukamy dwoch najmniejszych elementow, tj elementow z najmniejsza waga
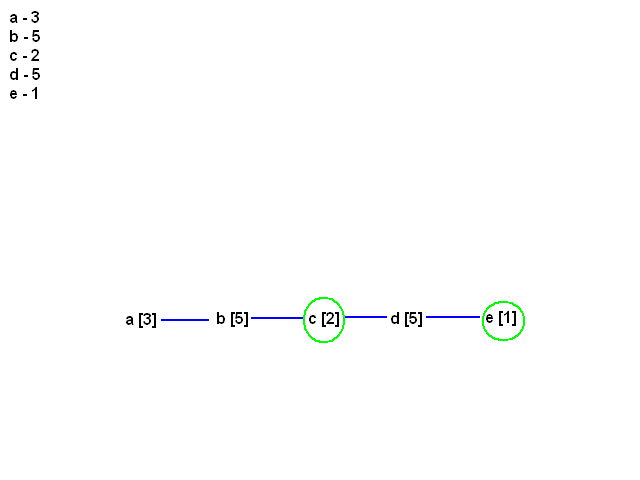
[21:14] <@Gynvael> to bedzie c[2] i e[1] w naszym przypadku
[21:15] <@Gynvael> nastepnie
[21:15] <@Gynvael> usuwamy te dwa elementy z listy
[21:15] <@Gynvael> ale zapamietujemy
[21:15] <@Gynvael> i dodajemy nowy element do listy
[21:15] <@Gynvael> bez znaku
[21:15] <@Gynvael> natomiast z waga, bedaca suma wag tych usunietych elementow
[21:15] <@Gynvael> czyli 2 + 1 == 3
[21:15] <@Gynvael> i dodajemy ten elemnet do listy
[21:15] <@Gynvael> i dodajemy mu prawe i lewe dziecko - elementy usuniete
[21:15] <@Gynvael> http://furio.vexillium.org/~wyklady/pack/huff03.png
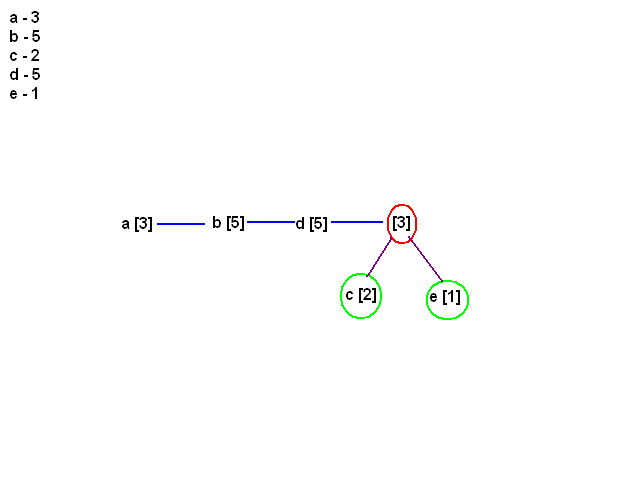
[21:16] <@Gynvael> kontynuujemy to samo
[21:16] <@Gynvael> szukamy dwoch najmniejszych elementow
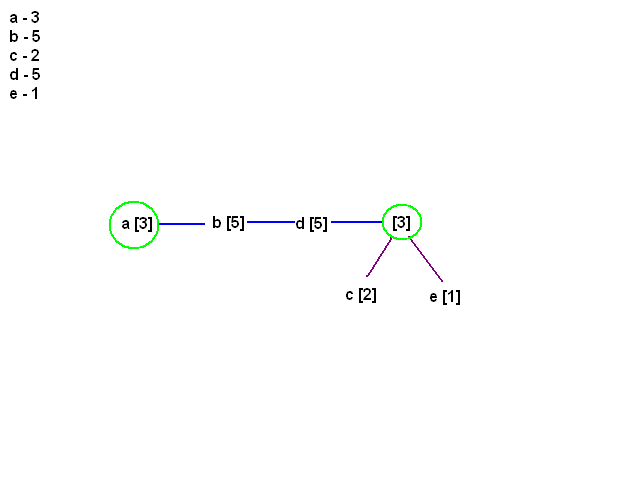
[21:16] <@Gynvael> usuwamy je z listy
[21:16] <@Gynvael> po czym tworzymy nowy elemnt
[21:16] <@Gynvael> z waga 3+3 = 6
[21:16] <@Gynvael> i dodajemy go do listy
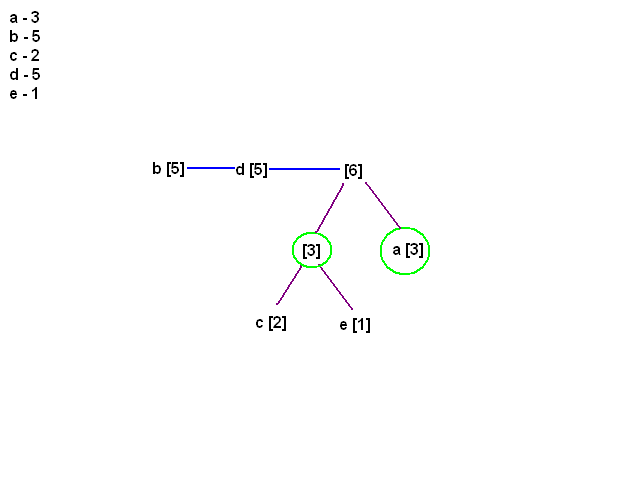
[21:17] <@Gynvael> ktore dziecko na ktore ramie dodamy nie ma znaczenia ;>
[21:17] <@Gynvael> i dalej to samo...
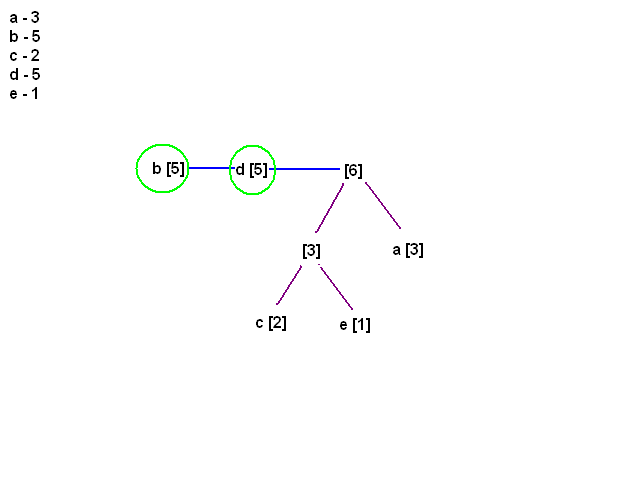
[21:17] <@Gynvael> teraz b i d maja najmniej
[21:17] <@Gynvael> wywalamy, dodajemy nowy element
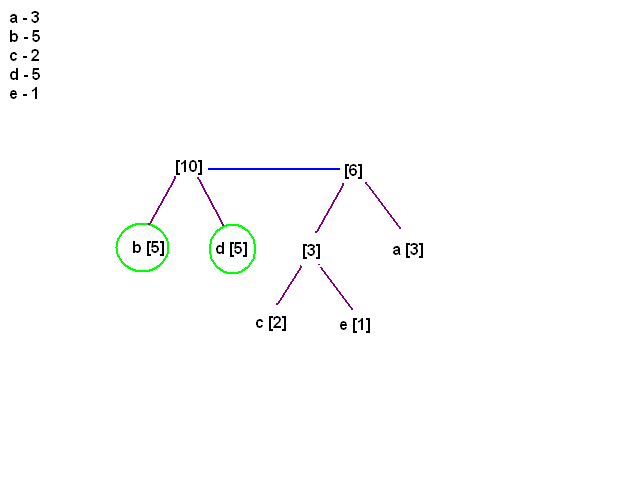
[21:18] <@Gynvael> i dalej
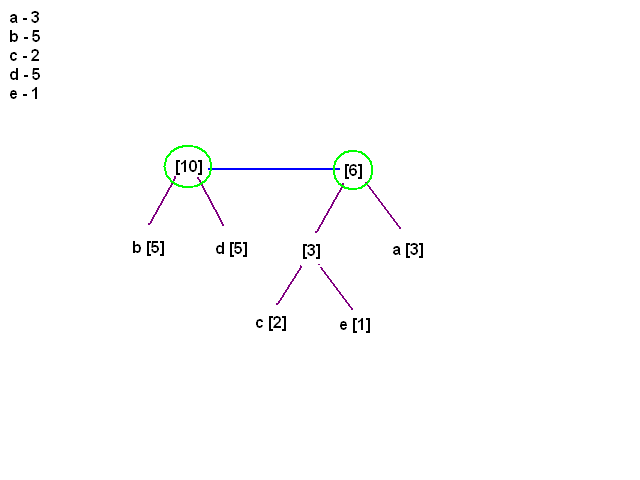
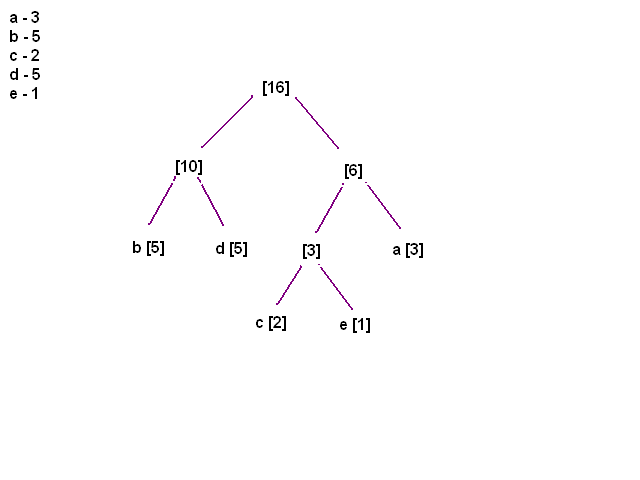
[21:18] <@Gynvael> i przeksztalcilismy liste w drzewo
[21:19] <@Gynvael> na tym konczymy tworzenie drzewa
[21:19] <@Gynvael> teraz tak
[21:19] <@Gynvael> patrzymy na to drzewo jak na mape
[21:19] <@Gynvael> stoimy na samej gorze drzewa
[21:19] <@Gynvael> i mamy dwie drogi
[21:19] <@Gynvael> lewo, prawo
[21:19] <@Gynvael> zalozmy ze chcemy dojsc do elementu 'e'
[21:20] <@Gynvael> musimy isc wiec w lewo, prawo, lewo (albo patrzec na to z perspektywy kogos przed monitorem, prawo, lewo, prawo)
[21:20] <@Gynvael> zalozmy wiec
[21:20] <@Gynvael> ze zapiszemy ruch w lewo (nasze lewo) jako 0
[21:20] <@Gynvael> a w prawo jako 1
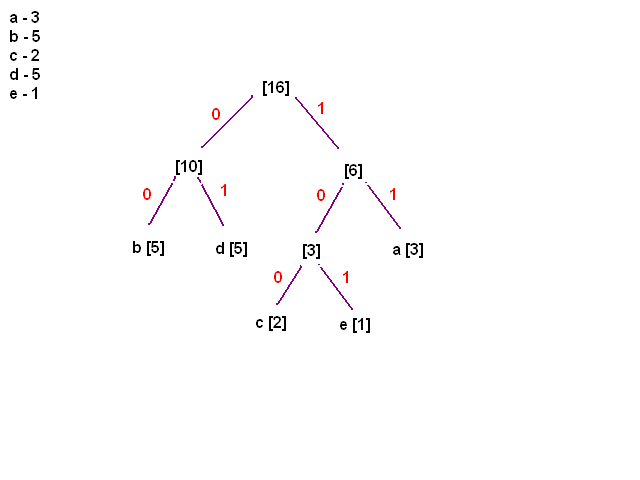
[21:21] <@Gynvael> kod danej litery
[21:21] <@Gynvael> to jest zapis drogi
[21:21] <@Gynvael> jaka musimy do niej przejsc
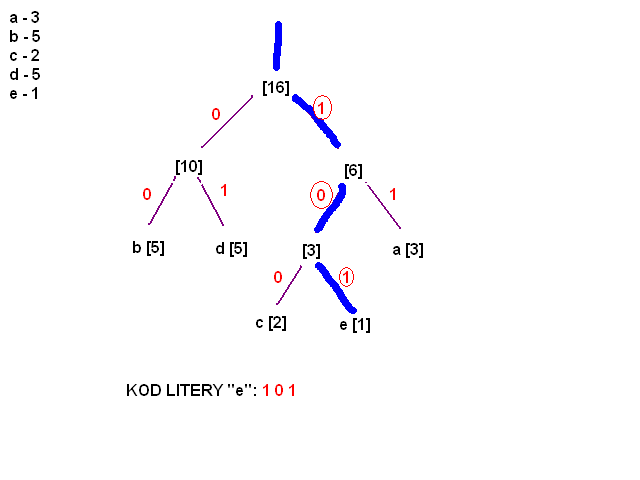
[21:21] <@Gynvael> w tym wypadku kod litery 'e' to jest 1 0 1
[21:21] <@Gynvael> wypiszmy kody wszystkich liter:
[21:21] <@Gynvael> a - 11
[21:22] <@Gynvael> b - 00
[21:22] <@Gynvael> c - 100
[21:22] <@Gynvael> d - 01
[21:22] <@Gynvael> e - 101
[21:22] <@Gynvael> razor_pl slusznie zauwazyl ze w przypadku takiej kompresji, nalezy pamietac aby kod jednej litery, nie byl poczatkiem kodu drugiej
[21:23] <@Gynvael> tj jej prefixem
[21:23] <@Gynvael> na szczescie ten algorytm wyznacza dobre kody ;>
[21:23] <@Gynvael> wiec nie musimy tego sprawdzac
[21:23] <@Gynvael> samo drzewo natomiast
[21:23] <@Gynvael> nie jest jednoznaczne
[21:24] <@Gynvael> moglismy np zamienic ze 0 jest po prawej
[21:24] <@Gynvael> a 1 po lewej
[21:24] <@Gynvael> albo ze b jest prawym a nie lewym dzieckiem
[21:24] <@Gynvael> ew ;>
[21:24] <@Gynvael> *etc
[21:24] <@Gynvael> ale to bez roznicy
[21:24] <@Gynvael> wazne zeby algorytm kompresujacy byl spojny jesli chodzi o wybor elementow z algorytmem dekompresji
[21:24] <@Gynvael> ale ok
[21:24] <@Gynvael> mamy kody
[21:24] <@Gynvael> teraz skompresujmy ciag
[21:25] <@Gynvael> "aaabbbbbccddddde"
[21:25] <@Gynvael> taki ciag jest
[21:25] <@Gynvael> to jest 16 * 8 bitow
[21:25] <@Gynvael> czyli 128 bitow
[21:25] <@Gynvael> zapiszmy wiec znaki zgodnie z wygenerowanym slownikiem
[21:25] <@Gynvael> -=212300=- <@Gynvael> a - 11
[21:25] <@Gynvael> -=212305=- <@Gynvael> b - 00
[21:25] <@Gynvael> -=212314=- <@Gynvael> c - 100
[21:25] <@Gynvael> -=212317=- <@Gynvael> d - 01
[21:25] <@Gynvael> -=212321=- <@Gynvael> e - 101
[21:25] <@Gynvael> o tym slownikeim
[21:25] <@Gynvael> bedzie to"
[21:25] <@Gynvael> :
[21:26] <@Gynvael> "11 11 11 00 00 00 00 00 100 100 01 01 01 01 01 101"
[21:26] <@Gynvael> po pogrupowaniu w bajty wychodzi
[21:26] <@Gynvael> "11111100 00000000 10010001 01010101 101"
[21:26] <@Gynvael> czyli (przy zaokragleniu w gore) 5 bajtow
[21:26] <@Gynvael> w przypadku RLE przypominam ze wyszlo 10 bajtow
[21:27] <@Gynvael> wiec wynik jest 2 razy lepszy
[21:27] <@Gynvael> (tj RLE bez markerow)
[21:27] <@Gynvael> ale...
[21:27] <@Gynvael> no wlasnie
[21:27] <@Gynvael> jest ale
[21:27] <@Gynvael> musimy zapisac slownik
[21:27] <@Gynvael> albo histogram
[21:27] <@Gynvael> w sumie zazwyczaj sie zapisuje histogram ;>
[21:27] <@Gynvael> a histogram to niestety dodatkowe 10 bajtow
[21:27] <@Gynvael> przynajmniej w tym przypadku
[21:27] <@Gynvael> na szczescie tak na prawde
[21:27] <@Gynvael> to histogramy zajmuja duzo mniej
[21:27] <@Gynvael> niz to co kompresujemy
[21:28] <@Gynvael> wiec tym sie nie ma co przejmowac, ale nalezy o tym pamietac
[21:28] <@Gynvael> -=212912=- <@Robol> czyli im dluzszy tekst do zaszyfrowania tym wieksza skutecznosc
[21:28] <@Gynvael> raczej 'tym mniej wielkosc histogramu jest zauwazalna'
[21:28] <@Gynvael> ;>
[21:28] <@Gynvael> slabym punktem tego algorytmu sa przypadki
[21:29] <@Gynvael> kiedy kazdy znak wystepuje podobna ilosc razy
[21:29] <@Gynvael> np plik wygenerowany z cat /dev/urandom > plik bedzie bardzo kiepsko skompresowany
[21:29] <@Gynvael> (jesli wogole)
[21:29] <@Gynvael> (poniewaz to generuje ciagi losowe o rozkladzie jednostajnym, czyli ze wszystkie znaki wystepuja podobna ilosc razy)
[21:30] <@Gynvael> dodam na pocieszenie ze wiekszosc algorytmow wymieka na ciagach losowych
[21:30] <@Gynvael> ;>
[21:30] <@Gynvael> natomiast najlepszym przypadkiem dla tego algorytmu
[21:31] <@Gynvael> sa ciagi gdzie znaki wystepuja rozna ilosc razy, w ten sposob ze kazdy kolejny znak ma dwa razy wiecej wystapien niz jakis inny
[21:31] <@Gynvael> np
[21:31] <@Gynvael> a - 1, b - 1, c - 2, d - 4, e - 8, f - 16, g - 32, h - 64
[21:31] <@Gynvael> etc
[21:32] <@Gynvael> teraz pare slow o wariacjach huffmana
[21:32] <@Gynvael> i kompresji tekstu napisanego w danym konkretnym jezyku
[21:32] <@Gynvael> zaczne od tego drugiego
[21:33] <@Gynvael> jak w sumie kazdy kryptograf wie, kazdy jezyk ma charakterystyczna dla siebie czestosc wystepowania kazdego znaku
[21:33] <@Gynvael> np w jezyku polskim najczesniej wystepujaca literka jest litera 'a'
[21:33] <@Gynvael> bodajze 'i' jest drugie ;>
[21:34] <@Gynvael> wiec mozna statycznie zrobic histogram
[21:34] <@Gynvael> i slownik
[21:34] <@Gynvael> dla takich plikow
[21:34] <@Gynvael> ale...
[21:35] <@Gynvael> mozna tez zastosowac jeszcze inne podejscie
[21:35] <@Gynvael> mianowicie zbadac jakie litery wystepuja najczesciej po kazdym znaku
[21:35] <@Gynvael> tzn np jaka litera wystepuje najczesciej po 'a'
[21:35] <@Gynvael> jaka po 'b'
[21:35] <@Gynvael> etc
[21:35] <@Gynvael> tak ze wkoncu dostaniemy powiedzmy 256 drzewek
[21:35] <@Gynvael> co ciekawe
[21:36] <@Gynvael> dla niektorych ciagow dostajemy niektore znaki 'gratis'
[21:36] <@Gynvael> np zalozmy ze po znaku '|' zawsze wystepuje znak 'a'
[21:36] <@Gynvael> wtedy ten znak 'a' jest kodowany zerowa iloscia bajtow ;>
[21:36] <@Gynvael> natomiast znacznie rosnie w takim przypadku wielkosc slownika ;>
[21:37] <@Gynvael> wezmy jeszcze inny sposob
[21:37] <@Gynvael> zamiast szukac histogramu dla znakow
[21:37] <@Gynvael> poszukajmy dla sylab
[21:37] <@Gynvael> albo takze dla sylab
[21:37] <@Gynvael> i dodajmy do listy 20 najczesciej wystepujacych sylab
[21:37] <@Gynvael> i skompresujmy w ten sposob
[21:38] <@Gynvael> mozna sie tutaj popisac fantazja ;> jesli chodzi o sposoby tworzenia tego drzewa i histogramu
[21:38] <@Gynvael> ok
[21:38] <@Gynvael> jako ze czas powoli dobiega konca
[21:39] <@Gynvael> to obawiam sie ze rodzine LZ oraz kody tunstala beda na nastepnym wykladzie
[21:39] <@Gynvael> jesli oczywiscie ten uzyska pochlebne opinie ;>
[21:39] <@Gynvael> opinie po wykladzie bedzie mozna http://forum.wyklady.net/index.php?topic=19.0 <=- tam wyrazac
[21:39] <@Gynvael> ok
[21:39] <@Gynvael> dzisiaj powiem jeszcze o tzw diffrence encoding
[21:40] <@Gynvael> jest to jedna z metod na ulepszenie kompresji
[21:40] <@Gynvael> wezmy sobie ciag
[21:40] <@Gynvael> ciag liczb
[21:40] <@Gynvael> 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 36, 36, 36, 36, 36, 35, 35, 34, 33, 32
[21:41] <@Gynvael> jak latwo zauwazyc, ciag jest regularny
[21:41] <@Gynvael> ale RLE by na nim sie nie sprawdzilo
[21:41] <@Gynvael> tak samo huffman by duzo nie dal
[21:41] <@Gynvael> natomiast zastosujmy pewna sztuczke
[21:41] <@Gynvael> mianowiscie
[21:41] <@Gynvael> zapiszmy pierwszy element w ciagu normalnie
[21:42] <@Gynvael> a kazdy kolejny jako roznice miedzy poprzednim a danym alementem
[21:42] <@Gynvael> czyli
[21:42] <@Gynvael> 23 normalnie
[21:42] <@Gynvael> a potem 24-23
[21:42] <@Gynvael> 25-24
[21:42] <@Gynvael> 26-25
[21:42] <@Gynvael> etc
[21:42] <@Gynvael> czyli
[21:42] <@Gynvael> 23, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, -1, -1, -1, -1, -1
[21:42] <@Gynvael> taki ciag bardzo latwo odtworzyc oczywisice
[21:43] <@Gynvael> po prostu dodajemy kolejne elementy rekursyjnie do poprzedniego
[21:43] <@Gynvael> 23, 23+1 == 24, 24+1 == 25, etc
[21:43] <@Gynvael> a taki ciag jak nam wyszedl
[21:43] <@Gynvael> ladnie by sie kompresowal za rowno huffmanem jak i RLE
[21:44] <@Gynvael> tam jest maly blad
[21:44] <@Gynvael> przy 35, 35 jest -1 ,-1, a powinno byc ofc -1, 0
[21:44] <@Gynvael> thx netx0r
[21:44] <@Gynvael> ok
[21:45] <@Gynvael> niektore ciagi
[21:45] <@Gynvael> mozemy starac sie przyrownac do pewnych funkcji
[21:45] <@Gynvael> np jesli ciag ma wartosci rosnace i malejace na przemian,
[21:45] <@Gynvael> np
[21:45] <@Gynvael> 1, 3, 5, 2, -1, -4, -2, 0, 1, 3
[21:45] <@Gynvael> etc
[21:46] <@Gynvael> mozna sprobowac odjac od niego ciag stworzony funkcja sinus albo cos
[21:46] <@Gynvael> moze to wyjsc lepiej, nie musi
[21:46] <@Gynvael> takie roznice jednak czasem lepiej sie koduja
[21:46] <@Gynvael> niz oryginalny ciag
[21:46] <@Gynvael> ok
[21:46] <@Gynvael> na dzisiaj tyle
[21:46] <@Gynvael> dziekuje za uwage
[21:47] <@Gynvael> bedzie druga czesc wykladu ;>
[21:47] <@Gynvael> no chyba ze stwierdzicie ze byl fatalny ;p
[21:47] <@Gynvael> na drugiej czesci postaram sie pokazac, omowic i potestowac implementacje dekompresji RLE, kompresji huffmana
[21:47] <@Gynvael> przestawic teorie i implementacje algorytmow z rodziny LZ
[21:48] <@Gynvael> i ewentualnie pokazac pare 'filtrow' jak to diffrence encoding w akcji ;>
[21:48] <@Gynvael> dziekuje za uwage
[21:48] <@Gynvael> wyklad mozna komentowac na naszym forum http://forum.wyklady.net/index.php?topic=19.0
[21:48] <@Gynvael> zapraszam na jutrzejszy i kolejne wykladzy
[21:48] <@Gynvael> dziekuje