Paged Out! was always intended as a PDF+print zine, but the "print" part turned out to be pretty elusive. We actually did an initial test print of 500 copies in 2019 for a conference I've co-organized (Security PWNing), but that's it. Until last month that is, when we pretty much got back on track with prints — both free prints for events, and — additionally — print on demand if someone wants to buy a copy. We actually also updated the website with a lot of print-related information.
So let's cut to the chase — how to get printed Paged Out!?
You can buy it in the first print-on-demand online bookstore we onboarded: lulu.com/spotlight/pagedout Note: there's a normal edition, and there are sponsorship editions — there's no difference between them apart from the price and the back cover; get a sponsorship one if you want to show additional love for the zine :)
At the same time if you or your company would like to sponsor some Paged Out! prints for a specific event or in general, please let us know (prints AT pagedout DOT institute).
So far only issue #6 is available, but we're working on getting all of them out there, including older ones. We're basically going one by one, first #5, then #4, and so on.
Speaking of issues — Call For Articles for issue #7 now has a soft deadline: 30 June 2025
As usual, we're accepting technical 1-page articles about everything interesting related to computers, electronics, radio, and so on. See pagedout.institute/?page=cfp.php for details.
Note: We're having problems getting articles about retro computers, speedrunning, and movement techniques in games (e.g. Apex Legends), so if you can write about that, please do; and if you know someone who could write something about this, please ping them. Of course all the usual topics are welcomed too, as always.
It's the 20-year anniversary of the CONFidence conference! And it's happening next week (2-3 June) in Kraków, so don't miss out.
Furthermore, we've shipped 500 Paged Out! #6 issues there, so – if you're fast enough – you can grab one for free there :)
Enjoy CONFidence!
P.S. If you don't have a ticket my code might still work: GYN10
P.P.S. Huh, time flies, doesn't it. I think the first CONFidence I attended was in 2008. It's great to see this conference is still going strong and amazing to be a part of its program committee.
Initially I was supposed to write another article on something completely different, but then I randomly found myself digging into what CTRL+D actually does on Linux. And it turned out it does something different than I thought, so I decided to share my surprise in the form of an article posted at hackArcana. Here's the first section:
Linux Terminal: CTRL+D is like pressing ENTER
What I always thought—and I'm pretty sure I'm not alone in this—was that pressing CTRL+D in the terminal closes the standard input for the running process. Alternatively, I've heard that CTRL+D sends an "EOF signal" to the application. But if you actually think about it, it just doesn't make sense. After all, in Bash you can press CTRL+D if the line isn't empty, and nothing happens! Perhaps that's a terminal setting then which Bash changes? Or maybe something more, or—as is in this case—something less is going on. Let's investigate!
Somebody's wrong on the Internet
Apart from the correct answer—to which we'll get shortly—there are two lead answers on "what does CTRL+D in a terminal do" that can be found on the Internet. Both wrong.
It sends an EOF (End-of-File) signal/marker/character to the running program.
It closes the standard input of the running program.
The first answer is somewhat correct (we'll get to that later), but not in the way you think.
With the beta launch of my company's educational platform (hackArcana), I finally have a place to write more about the fundamentals of security and post more educational content. The first piece I've written for our new platform touches on the confusion around the terms "validation," "sanitization," "encoding," "escaping," and "filtering". Most readers will of course be familiar with these, but because they are casually used interchangeably, they might not know the actual difference between them. Here's the first section of the article:
During various discussions, I've noticed there is some confusion about what exactly sanitization, validation, escaping, as well as—to add to the list—encoding, and filtering, are. And how do they differ from each other? Furthermore, which should be applied where? If you're confused about these concepts, or just want to polish up your knowledge, you came to the right place.
Note: This is something that can come up during a job interview. It's also bound to come up in the real world when dealing with application architecture and security—e.g. In selecting a proper solution or to fix for your app, or to advise a programmer on one.
The Big Picture
Regardless of which method we're talking about, the end goal is always to be able to process the received input data in a safe way. Note that "process" might mean a whole range of different things here, from storing the data in the database, displaying it in a terminal or on a website, to e.g. feeding it to a deserialization engine.
What's also really common, is that the input data can be processed in an application in more than one way, where each method of processing might have different requirements with respect to the data it receives. This already signals that there's more to the topic than just selecting one method and calling it a day.
Given the above, the actual situation inside the application looks more like this (this is still a simplified picture):
"Hacker", as we in the bizz know well, carries different meanings for different people, and this can cause hilarious misunderstandings. Yesterday, the Polish TV network TVN aired the second part of an ongoing documentary about issues in NEWAG trains that were analyzed by Dragon Sector. Near the end, the documentary featured a recording from the November 2024 meeting of the Parliamentary Infrastructure Committee, which was meant to discuss the matter. During the meeting, one of the Members of Parliament took issue with the Dragon Sector team being referred to as "hackers"—the quote above is from him (translated from Polish).
This, of course, is nothing new—just another example of someone knowing the colloquial meaning of the word but not its specialized one. This disconnect has existed for at least the past 40 years.
This raises an interesting question—should we use the word "hacker" in formal settings (court, parliamentary committees, etc.), or would we be better understood if we opted for "cybersecurity specialist" or a similar term, as we often do on LinkedIn and other professional platforms?
Or perhaps we should continue using the word "hacker," as it serves as a great litmus test for whether the person we're discussing these topics with is truly familiar with the computer security industry and its terminology. It’s an unexpected but useful canary—or perhaps a reminder—that not everyone speaks "computer."
Returning to the original quote, and on a rather amusing note—or perhaps to balance things out—multiple departments of the Polish government are actively seeking to hire individuals with the "Certified Ethical Hacker" certification. In some cases, you can even get grants to earn it! Additionally, one can find information on government websites about how Dragon Sector was invited to the National Security Bureau to receive a commemorative letter of congratulations and symbolic gifts after winning the 2014 CTF season.
So, do we continue advocating for our specialized meaning of the word "hacker" in official settings? Or should we revert to something more neutral instead?
We have some amazing articles and art (finally!) for you in this issue – there are 68 pages altogether (including 2 by yours truly). Here's a high-level list of topics (in alphabetic order):
Art,
Algorithms,
Artificial Intelligence,
Cryptography,
File Formats,
GameDev,
Hardware,
History,
Networks,
OS Internals,
Operating Systems,
Programming,
Retro,
Reverse Engineering,
and Security/Hacking.
Anyway, if you'd like to be informed about Issue #6 once it comes out, here are some ways to achieve that:
It took us a while, but we're finally doing the first open webinar in English ("we" being my company – HexArcana). It's going to be "CVEs of SSH" presented by Dan Murray!
Dan basically spent the last few months digging into the SSH ecosystem, and has quite a lot of interesting stories to tell. During this talk he'll focus on a couple of high profile CVEs assigned to various SSH client/servers. You can expect technical insight, historical context and humorous anecdotes along the way as we demystify headline-grabbing issues.
The talk is free to attend, but you have to register at https://hexarcana.ch/workshops/cves-of-ssh. Once registered, you'll receive the link to the talk on Wednesday or Tuesday.
Details:
Speaker: Dan Murray
Date: 2024-11-21 8:00 PM GMT+1
Duration: ~1.5h
Price: Free (registration required)
Other: Recording will be available for a limited time (30 days).
In a few days we'll also announce a 1-day course on SSH led by Dan – that's for you folks who like to dig a bit deeper into the tools you use. Stay tuned!
I woke up in the morning, got to the desk in my home office, checked my email, discord, and the news. Then I switched from my desktop to my laptop and... there's no internet.
That's weird. I just browsed the net on my PC, so what's up with the laptop? Both are connected to the same network, so it's not the problem of the network not having connectivity. As such, the problem lies between my ISP's modem and the laptop (inclusive).
I started with disconnecting and reconnecting the ethernet network cable (it's a pretty stationary laptop, so I keep it wired). That didn't fix anything, apart from displaying a short spinning animation indicating it's trying to get an IP address assigned (a DHCP issue then?). Just to be sure it's nothing on the laptop side I did a reboot, and then power-cycled the nearest network switch for good measure as well. No luck.
Following up on the DHCP lead I logged into my home server, which runs the DHCP daemon... wait... what is this?
ssh: connect to host home server port 22: No route to host
So I moved the chair a bit to check my server rack, and found the home server dark. That's unusual. On closer inspection actually the LEDs on the motherboard next to the power/reboot buttons were lit. A minor explanation here: I use customized Open Benchtable mounts, so the mobo is easily accessible; at the same time it means there are no power/reboot buttons on the case – as there is no case – so I rely on mobos having power/reboot buttons directly on them (or, failing that, small buttons-on-PCBs that you hook into the normal case button connector on the mobo).
I clicked the power button, and... even the two last LEDs went dark. Not great. They did light back up a few seconds later though, so re-tried a couple of times, with the same result. The closest I got to a "fully functional and running server" was the CPU fan spinning up for 0.5 seconds.
At this point I had good news and bad news:
Good news: I found the problem! DHCP server is down because...
Obligatory FAQ note: Sometimes I get asked questions, e.g. on my Discord/IRC, via e-mail, or during my livestreams. And sometimes I get asked the same question repeatedly. To save myself some time and be able to give the same answer instead of conflicting ones, I decided to write up selected answers in separate blog posts. Please remember that these answers aren't necessarily authoritative - they are limited by my experience, my knowledge, and my opinions on things. Do look in the comment section as well - a lot of smart people read my blog and might have a different, and likely better, answer to the same question. If you disagree or just have something to add - by all means, please do comment.
Q: I love low-level exploitation and exploit development! How can I make this my whole career?
A: So to not bury the lead, the problem is that low-level exploitation is rarely needed in cybersecurity, and jobs where one works mostly on low-level exploitation are few and far between. Furthermore, these jobs are even more rare if one wants to stay away from the gray area of hacking and away from the black market. It's more common for low-level exploitation to be a small occasional part of another role.
DISCLAIMER: The goal of this post is not to discourage anyone from pursuing a career in low-level hacking, nor do I think that it isn't an important area of cybersecurity. Rather than that, the goal is to give folks enough information to think things through and plan their approach instead of walking into this blindly.
Last week I livestreamed solving Hx8 Teaser 2 challenge from the Google CTF 2024 Qualification Round's. As I know not everyone has time to watch a 3h livestream, here are highlight videos (3 parts):
I was invited by @pr1m4te to join him today on the SECURITYbreak podcast to chat about various recent events in security. A recording is already available – enjoy!
We have some amazing articles and art (finally!) for you in this issue – there are 68 pages altogether (including 2 by yours truly). Here's a high-level list of topics (in alphabetic order):
Art,
Artificial Intelligence,
Assembly,
Cryptography,
Demoscene,
File Formats,
Hardware,
History,
Programming,
Retro,
Reverse Engineering,
and Security/Hacking.
Anyway, if you'd like to be informed about Issue #5 once it comes out, here are some ways to achieve that:
Unfortunately, due to medical reasons within my immediate family, despite my plans and intentions, I will not be able to fly to Monday's/Tuesday's CONFidence'24, for which I would like to sincerely apologize to everyone. Don't worry, nothing bad has happened – it’s simply safer for me to be nearby at home for the next few days.
As a result: - Paweł Maziarz will be giving our joint presentation on his own – fortunately, Paweł is an absolutely excellent speaker and has a ton of his own material in the presentation (although he will still get a few slides from me). I'll add that we considered a hybrid model (Paweł in the room, me remotely), but ultimately, we feared that it simply wouldn’t work well. - I won't be able to sign books – I especially want to apologize to those who in recent months have asked where they can catch me to sign books, and to whom I said I would be at CONFidence. I will be in Krakow again in September, but you can always write to me (preferably on Discord) and ask about upcoming opportunities to get a signature. - I also won't be able to give a proverbial "high five" to all of you whom I wanted to see and talk to :( - I would also like to thank Paweł and Monika from PROIDEA for their understanding and empathy – as a speaker and conference organizer myself, I know that a suddenly unavailable speaker can greatly disrupt plans. - Paweł and I are considering doing a full version of the presentation online sometime – so that it can still take place in the originally planned form. We’ll let you know as soon as something is decided (though it's likely to still be in Polish). - To sweeten the situation, I’ll reveal that either during CONFidence or shortly after, PO!#4 will be released.
Despite the above, I wish everyone a successful CONFidence – fingers crossed that this will be the best edition ever! :)
Yesterday Andres Freund emailed oss-security@ informing the community of the discovery of a backdoor in xz/liblzma, which affected OpenSSH server (huge respect for noticing and investigating this). Andres' email is an amazing summary of the whole drama, so I'll skip that. While admittedly most juicy and interesting part is the obfuscated binary with the backdoor, the part that caught my attention – and what this blogpost is about – is the initial part in bash and the simple-but-clever obfuscation methods used there. Note that this isn't a full description of what the bash stages do, but rather a write down of how each stage is obfuscated and extracted.
P.S. Check the comments under this post, there are some good remarks there.
Before we begin
We have to start with a few notes.
First of all, there are two versions of xz/liblzma affected: 5.6.0 and 5.6.1. Differences between them are minor, but do exist. I'll try to cover both of these.
Secondly, the bash part is split into three (four?) stages of interest, which I have named Stage 0 (that's the start code added in m4/build-to-host.m4) to Stage 2. I'll touch on the potential "Stage 3" as well, though I don't think it has fully materialized yet.
Please also note that the obfuscated/encrypted stages and later binary backdoor are hidden in two test files: tests/files/bad-3-corrupt_lzma2.xz and tests/files/good-large_compressed.lzma.
A somewhat ancient yet pretty cool feature of web browsers are the bookmarklets. These are literally just javascript: code snippets saved as bookmarks – they are like the older and less capable siblings of typical browser extensions and are limited to being run when clicked and only in the context of the page you're currently looking at. Anyway, since I use two such bookmarklets pretty reguraly, I decided to share them with you.
P.S. If you decide to explore other bookmarklets out there, remember that random bookmarklet found on the internet may contain malicious code. In such case executing it might leak the page you're looking at, leak authentication information (session cookies), or even give an attacker interactive control over the page in said tab (which allows them to change settings, and at times e-mails or even the account password). So if you can't security-review a bookmarklet, popular extensions in good standing are a safer choice.
If you're wondering what is Paged Out!, it's an experimental IT/electronics magazine where each article has exactly one page – and we have 48 50 of these! And there's a mix of topics there. E.g. in Issue #3 we have:
Programming,
Networks,
Reverse Engineering,
Security/Hacking,
Cryptography,
Hardware,
Artificial Intelligence,
File Formats,
Art,
and Sysadmin stuff (we really need a better name for this category)!
This issue is a bit lacking in the areas of Retro (I guess PS4 isn't retro yet, but we do have some SuperH), Demoscene, Radio, and a few other topics. So, if you'd like to write something for us in these or other areas, we have some good news! Call For Articles for Issue #4 is open! Check out this page for details. Please please consider contributing to Paged Out! :)
At the same time I have to note that a lot has happened over the course of the last few years on the PO! side and if you're interested to get a glimpse behind the scenes, check out the editorial of Issue #3 (on the first page after the cover) as well as our Paged Out! Institute blog.
Since I started my coding livestreams again there is one common question, which I wanted to address in this blogpost: what is this weird howto command I'm using?
$ howto convert a set of jpegs into a pdf, assume 90 dpi A4 page
convert -quality 100 -density 90x90 -page A4 *.jpg output.pdf
$ howto block any access to tcp port 1234 using iptables
sudo iptables -A INPUT -p tcp --dport 1234 -j DROP
$ howto zoom in my webcam
v4l2-ctl --set-ctrl=zoom_absolute=300
$ howto encrypt a file using openssl with aes in authenticated mode
openssl enc -aes-256-gcm -salt -in inputfile -out outputfile
And yes, that is just ChatGPT over API. It's actually a super simple Python script based on their examples. See for yourself:
Last year I've fully rebuilt my PC setup and on the way I've learnt quite a lot about PCI Express from a PC builder's perspective. On Friday at 8PM CEST I'll be doing a 1 hour...ish talk about what every PC builder has to know about PCI Express to avoid making the same mistakes I made. I think it's a pretty fun talk that folks who like to build their own PCs will enjoy.
Livestream took place on 28th of July 2023, 8PM CEST. Recording is available below - enjoy (talk starts at 13:57)!
With the end of April I left Google's security team after a bit over 12 years to rest and build something of my own. Let's use this livestream as an opportunity to chat about what was and what's next.
Livestream is scheduled for 4th of July 2023. Recording will be available.
A few days ago I had a fun chat with Ange Albertini about secure design of file formats – a topic Ange has been passionately researching for some time now. One of the specific problems that we discussed were overlarge fields and how to approach them in a file format or communication protocol design in a way that makes certain that their handling is safe and secure by default. In this blogpost I wanted to discuss two of my ideas (neither of which is perfect) and related observations on this topic.
What is an overlarge field?
It's best to explain this using one of my favorite examples – same one I've used in my "How to find vulnerabilities?" blog post and in several talks.
In the GIF image format specification there is a field called LZW code size which holds the initial LZW compression code size in bits.
What exactly the value entails isn't really important for this discussion. What is however important is that said value must be between 3 and 12 (inclusive).
The second important piece of information is that the field holding this value is a typical byte (8-bit) field.
This of course means that while on paper the value should be between 3 and 12, technically the actual field in a GIF file can contain any value in the range of 0 to 255. I.e. the field is too large for the actual value it's supposed to hold and thus I call it an overlarge field1. 1 Do note that this isn't an official term, just something I'm going to use for the sake of this blog post.
While browsing the news in the morning I've found an article on Ars Technica titles "Developer creates “self-healing” programs that fix themselves thanks to AI". It's about Wolverine, which is an automated extension of what was demoed during the GPT-4 reveal, i.e. the perceived ability of GPT-4 to understand error messages and suggest fixes. Basically it works like this: it runs the script and if there's an error, it's fed to GPT-4 for it to decide what to do and how to fix it; rinse and repeat.
Speaking generally in context of Large Language Models, the obvious issue here is: what if the error message contains a prompt injection from an attacker? The answer is pretty obvious (especially that it has been demonstrated over and over again that it's rather hard to secure against prompt injections) – the code might be "fixed" in a bit of an unwanted way.
Disclaimer: I am not a lawyer. Furthermore, remember that laws differ between countries.
Let me preface this post by saying that I don't have answers – I have only (interesting) questions. And perhaps the answer to the question in the headline eventually will follow Betteridge's law of headlines anyway.
So what is all this about?
In reverse-engineering there is a concept called clean room design. In short, it's a method of "copying" (and I'm using this term very loosely) someone's implementation of an idea without infringing on their copyrights. And while the term is a bit more generic, I will focus on it's application to software (code). In short, the method boils down to 3 steps:
Reverse-engineers analyze the source software and prepare detailed documentation about how things look like and how they are done.
Lawyers review the documentation to make sure no piece of code was included (or more generally: no copyrightable items were included).
Software engineers implement a new piece of software based on this documentation.
A pretty common reverse-engineering CTF challenge genre for the hard/very-hard bucket are virtual machines. There are several flavors to this*, but the most common one is to implement a custom VM in a compiled language and provide it together with bytecode of a flag checker. This was the case for the More Control task from Byte Bandits CTF 2023 – the task this entry is about. The typical approach to these kind of challenges is to reverse the binary and "look" at the bytecode enough to understand the opcode format and write at least a disassembler (and ideally reimplement the VM in Python), and then to analyze what's going on in the bytecode itself. Sometimes however you can take a shortcut. This post is a semi-complete write-up of a side-channel based solution for the aforementioned task.
* Other flavors include: 1) not providing the VM binary, but providing network access to some "system" running on it where you can run bytecode you provide and observe results; 2) not providing the VM binary; this hard-core sub-genre is rare and requires players to determine opcode encoding by just looking at unknown bytecode, which they can't even execute; 3) instead of a flag checker you get something that writes out the flag, but it takes literal years to write it out - so it's a typical "optimize me".
Side-channel attacks
You can safely skip this section if you know what a side-channel is.
A side-channel is basically a somewhat obscure and somewhat hidden weak source of information about an observed process. For example, the main channel of information for a program is what you see as the output on the screen. A side-channel however could be e.g. CPU usage graph, computer's power usage, electro-magnetic emission, or electronic component sound emission. And – or maybe first and foremost – measuring elapsed time. Here's a typical example (pseudo-code... well, that's actually Python):
A few days ago I've posted RE category write-ups from the KnightCTF 2023. Another category I've looked at – quite intensely at that – was forensics. While this blog post isn't a write-up for that category, I still wanted (and well, was asked to actually) write down some steps I took to make Volatility work with MEMORY.DMP file provided in the "Take care of this" challenge series. Or actually steps I took to convert MEMORY.DMP into something volatility could work with. I have to add that I didn't get the flags for these challenges*, so again, this isn't a write-up.
* It turned out that the flags weren't based on the MEMORY.DMP – the sole resource provided – at all due to an oversight in challenge creation. It was a pretty amusing situation we've learnt about after the CTF, but what can you do.
Let's start by stating the problem: neither Volatility 2 nor Volatility 3 were able to use MEMORY.DMP as input. WinDBG on the other hand had no issues at all, so we knew the file was correct.
$ python2 vol.py --profile Win7SP1x64 -f ../MEMORY.DMP pslist
Volatility Foundation Volatility Framework 2.6
No suitable address space mapping found
Tried to open image as:
MachOAddressSpace: mac: need base
LimeAddressSpace: lime: need base
WindowsHiberFileSpace32: No base Address Space
WindowsCrashDumpSpace64BitMap: No base Address Space
WindowsCrashDumpSpace64: No base Address Space
...
If you're unfamiliar with Volatility, it's an open-source forensics framework written in Python 2 and Python 3 respectively, which allows an investigator to run queries on computer system's memory dumps. Technically it understands internal Windows and Linux kernel memory objects and can walk through them to do stuff like listing running processes, dumping console buffers or the content of the clipboard, digging through the registry (it's in-memory version), etc. See this example for instance. Pretty neat tool!
Some theory on how Volatility works
As said, the input is a system memory dump. These however come in different shapes and sizes, depending on how one might have acquired it. For example, the one common source is a Blue Screen of Death-time automatic memory dump creation – it's usual purpose is to allow folks to put it in WinDBG and figure out why the system crashed. Another typical example includes providing a raw dump of physical memory – these can be acquired in a multitude of ways, though they don't really include any useful metadata (will get to this later). Either way, usually what you get is a dump of physical memory – physical being the keyword here.
Physical memory however won't do. That's because the great majority of the kernel structures – as well as literally everything in user-land – operates on virtual memory. So the first thing volatility has to do is basically load the proper parser for the given input format and then provide a virtual memory view for it. This can of course be done easily based on the page table structure which maps virtual addresses to physical addresses.
One important thing to note here is that there isn't just one page table structure in memory. There are a lot of them – usually one per process, though in some cases even each thread might have one. That's OK however, since even if you find only a single page table in memory you'll be able to access the process/task/thread list, and these in turn hold physical addresses of their respective page tables. This means that each process/task/thread "sees different things" in memory, though usually at least the kernel part is seen by all of them in the same way.
On Friday/Saturday (yeah, right about when layoff news hit) I played a CTF for fun/to relax with some friends. Our choice was KnightCTF 2023and here are some writeups of the tasks I solved or helped solve (Reverse Engineering category only for now).
Update: Added a guest write-up for the Stegorev challenge by Sir P. Gently.
As the old IT joke goes, in holiday season all IT workers visit their families to fix their computer. This time for me however it wasn't about fixing a computer, but copying contacts from an old Sony Ericsson (SE) Android phone to a new MaxCom* MM721 comfort phone. I'm not really sure what OS its running, but the whole idea behind that device is that it's supposed to be really simple to use, with the target audience being e.g. older people. And the MM721 indeed is simple to the extreme. Simple enough that moving ~200 contacts from the old phone to the new one proved to be an interesting (programming) challenge, mostly because I definitely didn't want to do it manually.
* As an editor I try to always get capitalization of company/product names correct, but MaxCom is not making it easy. In the official User Manual for said phone the logo says "MaxCom", the title says "Maxcom", and the official company address says "MAXCOM". I will stick with MaxCom.
On paper the whole thing should go like this:
Write contacts on the old phone to the SIM card.
Put the SIM card in the new phone.
Optionally agree to copy the contacts from the SIM card to the new phone.
If you're used to smartphones and stick only with a given family – be it iOS or Android – this whole concept of using the SIM card might sound weird, since contacts are copied via the cloud, right? This device is just too simple for that – there is no cloud sync. Actually there's no web browser on it either.
In any case the issue was that the SIM card I had could only hold 150 contacts. And I had 200 to move. Well then.
Of course one might rightfully point out, that I could first move half of the contacts, use the aforementioned "copy the contacts from SIM to phone memory" option, and then move the second half. Unfortunately the automatic backup function on the device auto-selected always the first 150 entries, and then threw an error. I could have perhaps manually removed the first 150 contacts or manually marked the last 50 contacts as "stored on SIM" (I didn't check if that was an option on the SE device, but I'm guessing it was), but I really wanted to avoid having to stuff manually.
So instead I decided to look for a more automated solution. Was it faster in the end? Not sure to be completely honest. But at least it was pretty fun!
This is actually a follow-up to the last paragraph from my previous Debug Log. To save you some reading, I was trying to find which device causes boot delays on my PC. Eventually I traced it to a Bluetooth module, which – to my surprise – was a part of a detachable WiFi+BT module connected to a custom 20-pin header on the motherboard (electrically that was an M.2 key E, i.e. PCI-e x1 + USB). The afore mentioned last paragraph goes like this:
The only question that remains is whether one can attach a GPU through an adapter to this slot (will be pretty slow, especially that it's PCI Express x1 version 2.0 – since it's attached to the chipset and X99 does only PCIe 2.0). Not that there is any reason to do it. Anyway, I might or might not have ordered a proper cursed adapter from a certain Chinese electronics site, so guess we'll find out.
Well, the adapter arrived yesterday, so I took it for a spin. The rest of this blogpost consists mostly of photos.
SECCON CTF 2022 Quals are over and I have to say that the tasks which I looked at were of pretty amazing quality. The task that I started with was called "find flag" and was authored by ptr-yudai. While it's a tiny warmup challenge, I found it extremely clever! So, here's a writeup.
<PSA> Twitter is going great! Here's my new profile on Mastodon: @gynvael@infosec.exchange. Now back to our show! </PSA>
I woke up today, turned on my PC, went to the kitchen to put on water for a cup of tea and came back to a set of black screens. This is pretty weird as Haven – my main workstation (named after a city from one of my favorite book series) – while being a rather old computer starts pretty fast. But I patently waited and in a few seconds the typical BIOS/UEFI screen appeared followed by the OS booting... with some errors:
Greeted by errors
This wasn't the first time it happened – rather than that it had a tendency to come and go. And to add a few minutes to the boot time. Being me I decided it's a great opportunity to wasted an odd hour to trace (and hopefully fix) the issue of the few minute longer boot. And you're invited to join me on this debugging adventure!
The first step on the classic education path of future programmers is creating a program that prints – most often in the terminal – “Hello, World!”. The program itself is by definition trivial but what happens after it is launched is not – not entirely at least. In this article, we will trace the execution path of the "Hello World" micro-program written in Python and run on Windows, starting from a single call to the high-level print function, through the subsequent levels of abstraction of the interpreter, operating system and graphics drivers, and ending with the display of the corresponding pixels on the screen. As it turns out, this path in itself is neither simple nor short, but definitely fascinating.
Python code
The code we're going to start with is trivial:
print("Hello World")
The effect of its action is both predictable and obvious:
However, what makes our computer deem it appropriate to change the color of several hundred selected pixels on the screen when executing the above program?
Crow is an asynchronous C++ HTTP/WebSocket framework for creating "flask-like" web services. In early August we discovered a pretty interesting use-after-free vulnerability. Since Crow takes advantage of the Asio library for asynchronous input/output operations, analysis of this vulnerability took a few long evenings since the cause was split between multiple interweaved tasks and callbacks. Eventually we traced the root cause to an interesting mismatch between two layers of code, one of which - the HTTP parser - was supporting HTTP pipelining (or rather was agnostic towards it, which resulted in pipelining being inadvertently supported), while the other - HTTP server logic - was not designed to take HTTP pipelining into account. This resulted in some interesting "race conditions" with one task "thinking" an HTTP connection was over (and deleting objects) while another still using them while processing a separate HTTP request.
One thing to note is that we never proved exploitability (as in: actual RCE, since it's pretty easy to just trigger this vulnerability to cause a DoS) due to ENOTIME, though we believe it should be possible, if highly complex.
The vulnerability in question was reported mid-August and fixed within 6 days.
CVSS, CVE, etc
Human readable details are in the next section.
CVE: CVE-2022-38667
CVSS 3.1: 8.1 High (AV:N/AC:H/PR:N/UI:N/S:U/C:H/I:H/A:H) [as originally reported]
CVSS 3.1: 9.8 Critical (AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:H/A:H) [as rated by NIST/NVD]
Crow is an asynchronous C++ HTTP/WebSocket framework for creating "flask-like" web services. While analyzing another vulnerability we've found a Cloudbleed-like information disclosure bug in the code path responsible for serving static files. Technically no special action on attacker's side was required - it was enough to request a static file smaller than 16KB and the server would send the file padded with uninitialized stack content (up to 16KB) back.
The vulnerability in question was reported mid-August and fixed within 6 days.
CVSS, CVE, etc
Human readable details are in the next section.
CVE: CVE-2022-38668
CVSS 3.1: 5.3 Medium (AV:N/AC:L/PR:N/UI:N/S:U/C:L/I:N/A:N) [as originally reported]
CVSS 3.1: 7.5 High (AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:N/A:N) [as rated by NIST/NVD]
While writing an article on how "Hello World" actually works in Python (written with j00ru and Adam Sawicki, and published in 100th issue of the Polish Programista magazine; we'll publish the English translation on our blogs around September/October 2022) I've played a bit with Python's ast module (as in Abstract Syntax Tree) and decided it would make a cool CTF challenge if I would make some restrictions on AST level and have folks try to bypass it.
This wasn't of course the first challenge using AST on a CTF, though I did think to check only after I've already implemented it. Thankfully other challenges use different restrictions, so there was no collisions. Here are some of them though (leave a comment in case I've missed some):
Eventually the challenge was published at Google CTF 2022 in the Sandbox category under the name of Treebox and was solved 268 times, making it the easiest (or most popular? ;>) challenge of the CTF.
The challenge is likely still online when you're reading this blog post (if it's not, let me know) and you need only netcat to enjoy it. Just follow the link above, download the source code and have fun!
There are only 3 AST-level restrictions in Treebox:
you can't call a function,
you can't use import,
and you can't use import from.
What was wonderful about the way players solved it, was that every solution was unique in some way. There were of course clusters of solutions converging around this or that feature, but at the end of the day the solutions were pretty different.
Since the solutions contain spoilers, I've posted them in a separate note in case readers would like to try their luck first.
Warning SPOILERS: Treebox solutions (it's at the bottom of this set of notes)
Whether you try the challenge first or now, if you enjoy Python I greatly recommend looking at the solutions. They are extremely clever in some cases, and fun in every case.
Recently chatting with a friend I realized I can recall a lot of interesting stories of how players tried to abuse a given CTF tournament to gain an extra edge over the competition. So in this informal blog post I'll try to list what I remember for both the purpose of documenting this so others can learn from history, and also due to its fun factor (or rather: fun factor after a couple of years passed and folks stopped being annoyed or down right furious at the perpetrators). Note that some of what I'll log here are just stories I've heard. Other things I might have witnessed on my own. In either case I won't be posting any details of who / when / at what CTF – that's not the purpose of this post. Rather than that I'll try to distill and present the general concept.
Update: In case you're wondering what is a security CTF: it's team hacking competition, closely related to vulnerability research and cryptanalysis. You can read more on CTFtime.org and Wikipedia. End of update.
Please treat everything I've written with a grain of salt and excuse my human memory if I mix things up. I've been playing CTFs or CTF-like events for close to 20 years now, so yeah, mix ups might happen.
Please also note that these are stories of abuse and NOT a guide on how to play CTFs. Please DON'T do the stuff described here.
The back story of this debugging session is that I'm reworking a bit my home server. One of the things I'm doing is putting some more HDDs in there and sharing them over the network with my other computers. But since HDDs are a bit slow, I decided to add two M.2 NVMe SSD which I had lying around for caching (with bcache). Now this is a pretty old home server - I've built it in 2016 and used what even then was considered previous gen technology. This means it had only one M.2 slot, which was already used by the OS SSD. So the disks had to go the the PCI Express slots. For the disks themselves this isn't really a problem, as M.2 NVMe is basically PCIe in a different form factor. So just a simple (electrically speaking) adapter was enough. And while one of the SSDs worked well, the other was suspiciously slow.
Even if the PDUs you use in your data center aren't branded "Powertek", please keep reading.
Powertek is a company that makes datacenter class smart PDUs (Power Distribution Units - i.e. heavy duty power cords) for server racks. They sell both directly (or at least used to in the past I think?) and through their resellers. There is one reseller per country and they commonly rebrand their PDUs (e.g. mine has a logo of the Swiss reseller - schneikel).
Anyway, in March I've done a quick 3h review of the firmware and found multiple vulnerabilities and weaknesses in Powertek PDU's firmware v3.30.23 and possibly prior (details below). So, if you're using a PDU that is running Powertek firmware, you might want to patch now.
One more note on patch distribution though, because the situation is pretty substandard. The patch is made and was started to be distributed 30 days ago. However, for reasons which I don't fully understand Powertek decided to NOT distribute the new version of firmware publicly on their website, as is the standard way to do this. Instead, Powertek sent the patches to resellers and they were meant to distribute them to their clients (but they couldn't publish the patch either). UPDATE: schneikel expressed interest to work together with Powertek on improving this (cool!).
As you can imagine this leaves out any second-hand owners of these PDUs. If you are a second-hand owner of a PDU running on Powertek firmware, you have to reach out to your local reseller to get the patch (or to Powertek directly I guess).
And yes, I did try to convince my contact at Powertek that perhaps having security patches on their website is a good idea. Given that on their website I still see firmware 3.30.17 from December 2020 (which is even older than the one I've reviewed), I think I've failed. As a side note, parts of that website still contain "Lorem ipsum" fillings, so... I guess the website isn't Powertek's favorite child?
Google CTF nowadays is a pretty large event - or should I say 3 connected events, with the pretty hardcore main CTF being one of them, and Hackceler8 - where speedrunning meets CTFs and game hacking - being the second. The last one, but probably the most popular one is Beginners Quest - a set of CTF challenges tied together with a story (a 001337 spy story in this specific case) and aimed at folks who like challenges, but prefer to take it easy is a stress free (i.e. no scoreboard) environment. Anyway, yesterday I've made an over 4 hour long livestream where I've solved all the challenges from this year's BQ, and here's the recording - enjoy!
Timeline (in order of solving):
15:46 - Task 1: CCTV (rev)
23:38 - Task 2: Logic Lock (misc)
34:27 - Task 3: High Speed Chase (misc)
49:25 - Task 5: Twisted robot (misc)
1:07:50 - Task 8: Hide and seek (misc)
1:22:10 - Task 10: Spycam (hw)
1:47:15 - Task 12: Old lock (web)
1:55:47 - Task 13: Noise on the wire (net)
2:04:45 - Task 15: Just another keypad (rev)
2:14:48 - Task 17: Playing golf (misc)
3:01:08 - Task 18: Strange Virtual Machine (rev)
3:41:49 - Task 4: Electronics Research Lab (hw)
3:51:41 - Task 6: To the moon (misc)
4:16:40 - Task 7: ReadySetAction (crypto)
4:25:30 - Task 9: Konski-Hiakawa Law of Droids (rev)
4:28:23 - Task 11: pwn-notebook (pwn)
4:41:59 - Task 14: web-quotedb (web)
4:45:04 - Task 16: Hash-meee (misc)
TL;DR: NETGEAR just patched 3 reported vulnerabilities (Demon's Cries, Draconian Fear and Seventh Inferno) in some managed (smart) switches. If you or your company owns any of these devices, please patch now.
P.S. This vulnerability and exploit chain is actually quite interesting technically. In short, it goes from a newline injection in the password field, through being able to write a file with constant uncontrolled content of 2 (like, one byte 32h), through a DoS and session crafting (which yields an admin web UI user), to an eventual post-auth shell injection (which yields full root).
TL;DR: NETGEAR just patched 3 reported vulnerabilities (Demon's Cries, Draconian Fear and Seventh Inferno) in some managed (smart) switches. If you or your company owns any of these devices, please patch now.
Note: Details on Seventh Inferno will be publish on or after 13th September.
TL;DR: NETGEAR just patched 3 reported vulnerabilities (Demon's Cries, Draconian Fear and Seventh Inferno) in some managed (smart) switches. If you or your company owns any of these devices, please patch now.
Note: Details on Seventh Inferno will be publish on or after 13th September.
Two weeks ago I played 0CTF/TCTF 2021 Quals CTF with my team. As every year, it was a pretty fun CTF, though in all honesty I observed only one challenge - pypypypy. Without going into too many details, it was a Python sandbox escape challenge where the player controlled only Python bytecode (limited to 1000 bytes - that's 500 instructions). Yes - only bytecode, i.e. no constants, no local or global variable names, etc (with a minor exception, but that's besides the point). Given this, I had to come up with a way to make strings out of thin air, and before that, make integers out of thin air as well.
Making integers isn't actually that hard, since it's quite easy to get False or True on the stack (e.g. with 2 times BUILD_LIST, 0 followed by a COMPARE), and these get implicitly converted to 0 and 1 respectively when used in any math operations. Having a 1, I implemented a method that just kept left-shifting it (to get 1, 2, 4, 8, 16, 32, 64, ...) and selectively duplicating the values on the stack to add them later - this is basically how the binary system works anyway (and it's quite similar to Russian peasant multiplication method). This worked, but...
As I mentioned above, the total number of instructions was effectively limited to 500, and the above method – while it worked – generated waay too long operation sequences. So I had to figure out a new approach.
In the end I decided not to do it. Or rather, I decided to let my computer figure out what's the shortest way to create a constant number having the value 1 on the stack (technically it should have been True instead, but whatever).
Just a short reminder to anonymize data on the server-side
and not in the browser, illustrated by a small privacy vulnerability I've
found during, well, a security talk I've attended that took place on the
ClickMeeting platform (it was still 10 minutes before the talk began you
understand).
Props to ClickMeeting for a fast reaction time and good communication - this
bug is long fixed (reported on April 7th 2021).
Since there were some questions about "why is this a bad pattern?", I decided to write a short blog post explaining this.
But before we get there, please also see this short thread, or just remember to not blame an individual engineer for writing that code – rather blame the procedures NETGEAR has with regards to secure code development and quality assurance.
As mentioned in previous post, NETGEAR WAC104 access point just had a couple of vulnerabilities patched and you should upgrade its firmware now if you own such a device at your company or at home (or anywhere else).
Note that while the advisory mentions only the auth bypass vulnerability, the fix actually addresses all 5 vulnerabilities reported in this chain (see the original report below).
Just a short post (I will publish a longer one with details on Monday) – if you have the following NETGEAR access point, you should upgrade your firmware now:
WAC104
NETGEAR's advisory and the firmware can be found here:
Please note that NETGEAR assigned CVSS v3.1 score of 8.8 (High), which is incorrect (unless I misread the CVSS specification) - it's actually 9.8 (Critical): Vector String: CVSS:3.1/AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:H/A:H
This firmware fixes also a couple of other vulnerabilities with lower CVSS scores. More details on Monday.
P.S. This vulnerability chain is dubbed Gears of Chaos (in line with my sense of humor).
Obligatory FAQ note: Sometimes I get asked questions, e.g. on IRC, via e-mail or during my livestreams. And sometimes I get asked the same question repeatedly. To save myself some time (*cough* and be able to give the same answer instead of conflicting ones *cough*) I decided to write up selected question and answer pairs in separate blog posts. Please remember that these answers are by no means authoritative - they are limited by my experience, my knowledge and my opinions on things. Do look in the comment section as well - a lot of smart people read my blog and might have a different, and likely better, answer to the same question. If you disagree or just have something to add - by all means, please do comment.
Q: How to find exploits in software?
Q: How did you find this CVE? (in context of a vulnerability with no CVE assigned) Q: How to create an exploit for ThisOrThatApplication?
and also Q: I want to work in security, do I need CVEs?
Null Byte Poison is a neat little attack that usually can be applied when "length+data"-type strings get converted into "zero-terminated"-type strings. It's a well known problem though that haunted PHP scripts for several years, and even visited the browser world. Nowadays a lot of languages (or rather: runtime environments of these languages) have built-in protections against it (including PHP!) - for instance see this Python example:
>>> open("\0")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: embedded null character
Unicode brought another similar problem to the table in the form of two ways (one invalid-yet-working) to encode a Null Byte without using an actual \x00 byte - this allows to, depending on the scenario, either bypass a Null Byte Poison detection, or actually inject a Null Byte into a "zero-terminated"-type string at a later processing stage (which is sometimes useful):
UTF-8 overlong sequence: \xC0\x80
UTF-7 being UTF-7: +AAA-
In the above cases when the strings get decoded to Unicode we (might) see Null Bytes popping up in the data. Thankfully all decent UTF-8 decoders deal properly with overlong sequences and nothing modern uses UTF-7 anyway (with the notable exception of Express.JS in some scenarios).
While playing with a path traversal bug in mutool (details below) I've found yet another Unicode-related way to inject a Null Byte into a string. This method actually relies on a decoder bug and is pretty case-specific, but I think it's worth testing for as I wouldn't be surprised to find it again in similar scenarios in the future.
The bug in question resided in this code (mupdf/source/fitz/time.c):
From time to time I am asked to look at someone’s CV/resume and to suggest improvements. Usually, apart from o bunch of tips/comments, I give that person a link to a 10-year old blogpost of mine which enumerates things a programing/hacking enthusiast might have done and could include on their resume - some of them are obvious, others less so. Originally the blogpost was published in Polish; however, a few days ago I had it translated, I've updated it, and here we are - enjoy!
Here’s the usual problem: how to document the knowledge acquired on your own?
I found a fun question in my inbox today: If an application downloads a ZIP file with an update, what is the probability of the ZIP being corrupted? And should the update's hash (e.g. SHA256) be always attached as well? Let's take a look at the details.
There are basically two parts to the answer - the probability itself, and best practices.
Starting with the first one, let's consider a typical "download stack", i.e. HTTP over SSL over TCP over IP, and the ZIP file format itself. There are 3-4 mechanisms in play that need to be considered here:
TCP packet's checksum: It's a 16-bit value, meaning (and slightly simplifying the problem to a rule-of-thumb) that if the transmitted data gets corrupted, there is a 1/216 (or ~0.15%) chance of the corruption not getting detected by the checksum. In practice if you're transmitting a lot of data (e.g. 1 GB) through a noisy medium (e.g. some form of radio), you're basically guaranteed to run into this problem.
SSL/TLS (H)MAC/AEAD: Long story short SSL/TLS tries to do its best to protect the payload from being corrupted on purpose by a third party. Depending on the version this was done by either calculating a 128/256-bit MAC of the data (i.e. hash-based Message Authentication Code), or using AEAD (Authenticated Encryption with Associated Data). In general, it can be assumed that either approach will detect accidentally corrupted data, i.e. the probability of a corruption accidentally colliding a hash is basically non-existant, or 0.00000000000000000000000000000000000029% for 128-bit MACs, 0.00000000000000000000000000000000000000000000000000000000000000000000000000086% for 256-bit MACs, and so on.
ZIP's CRC32: A 32-bit value. Not cryptographically safe (actually quite unsafe in fun and interesting ways, but that's for another time), but it still should be able to detect most corruptions that happen to file data in the ZIP archive (but NOT to ZIP headers and e.g. file names; even though file names are in two places in a ZIP files, almost no ZIP extractors compare both file names against each other).
In addition every protocol parser (and the ZIP parser) on the way might detect corruption in the headers (though this isn't guaranteed). Also lower level protocols (e.g. Ethernet's FCS) might detect some corruptions - they usually also use 16- or 32-bit checksums.
So in the end, if we use HTTPS we should be safe, at least from corruptions made during transit (most of them are). However, if a corruption would be introduced e.g. while the data is still being handled on the sender's side (and a cosmic ray would hit the CPU in the right place), then by the time the data is safely transmitted through SSL it's already too late. So an additional update hash would save the day.
What about current best practices?
Basically it's recommended that downloadable updates are cryptographically signed with a private key, and after the download is complete, the application checks whether the signature is correct using a public key (that's hardcoded in the application). This way apart from detecting accidental corruptions, we're also stopping a potential attacker from supplying their own update package (e.g. after hacking the update server). Of course this means now we have to protect the private key and somehow safely incorporate it into our build process, but at the end of the day it's probably worth it.
The deadline for Gynvael's Summer GameDev Challenge 2019 was today around 2PM Zurich time, and since there weren't a lot of submissions (actually, there was only one), I expedited selecting the winner and awarding prizes.
Given the above, please join me in congratulating the sole winner of GSGC 2019!
1. Shutterbug by RustiSub (prize: 300 USD giftcard)
The vector graphics requirement seemed to be a pretty hard one - I'm pretty sure this contributed to the uncommonly low participation - yet RustiSub's game's graphic style is spot on and is an excellent proof that you can do quite a lot with just vectors (one of the reasons I've decided to increase the prize by 50%). Yet I feel we've barely scratched the surface, so vectors will be back - though most likely as part of other, smaller competitions.
The next event in this constrained game dev challenge series will be Gynvael's Winter GameDev Challenge 2019/20 - look out for it around December 2019!
Our CTF team - Dragon Sector - is organizing a teaser CTF this weekend. There will be one or two tasks from me too, so... I wish you luck! Details follow.
Teaser Dragon CTF 2019:
When: Sat, 21 Sept. 2019, 12:00 UTC — Sun, 22 Sept. 2019, 12:00 UTC
The prizes are planned in a way to ease up traveling to the main event (Dragon CTF 2019) and they assume 4-person teams (max):
Top1 - Top3:
Invitation to the offline event (i.e. you don't have to buy a conference ticket).
Travel allowance (cap depending on travel distance).
Hotel (2 twin rooms, 3 nights).
Top4 - Top10:
Invitation to the offline event (i.e. you don't have to buy a conference ticket).
Hotel (2 twin rooms, 3 nights).
The main event is the Dragon CTF 2019, which will take place 14-15th November in Warsaw, Poland, during the Security PWNing Conference (the conference is mostly in Polish, with the international CTF being an exception). The CTF itself is an offline, jeopardy, team (4 people max), ranked tournament, and it's an event open to all conference participant. This means you don't have to qualify to play, but you need to hold a conference ticket (or conference invitation from the Teaser prizes above).
Summer is almost over, but there is still time for Gynvael Summer GameDev Challenge 2019 - nobody's favorite gamedev competition with a set of arbitrary constrains/limitations put in place just to make it more challenging! And there are even prizes!
Newest rule update: 2019-08-31 (initial version, no changes yet)
P.S. If you actually like this challenge, please help spread the word around - there were 25 submissions last time, and we would love to beat that record!
First issue of our new experimental, very technical, and well - geeky zine is nearing it's completion. We currently have 45 article submissions (with 50 being the minimum goal), and so I wanted to let you know that if you want your article to be in the 1st issue of Paged Out!, please send the article in by 30th July 2019. On the 30th we'll start putting the issue together (which is expected to take a few days) and pushing the last articles through reviews, so hopefully you should get a "beta" or "release-candidate" version of Paged Out! (for free!) at the beginning of August (unless we run into serious problems with our PDF scripts).
and from cpython_exploit_ellipsis import * by disconnect3d (in form of an ad printed in Polish Programista magazine; expect a PDF on the main Paged Out! site in a few days).
Long story short: I've started a new project - Paged Out! - a free deeply technical magazine about programming/retro/hacking/security/electronics/demoscene/etc, where each article is limited to exactly one page. And today we're officially starting the Call For Pages (or call for papers/articles/whatever you want to call it) for the first issue.
Please help up spread the word - I don't know every amazing potential author on our technical scene, but all of you together DO! Plz help :) (If you're also interested in helping out in another way, please also take a look at this page.)
Long story long:
As some of you know for several years I've been a technical reviewer for the "Programista" magazine (as the name implies, it's a Polish magazine about programming), and before that I helped in a similar role (for shorter time periods) in other magazines as well (HITB Magazine, and another one which we don't name nowadays). One common thing I've noticed about the articles is that almost all of them are pretty long (like 10 pages in print, or 20 pages in "source" form). The length is usually the result of the selected topic, author's desire to explain everything in sufficient detail, and lengthy well formatted code listings with verbose comments.
That's just how programming articles must be, right?
As some of you might know, I already had a set of two IRC channels on irc.freenode.org for my livestreaming community (hi!). However recently I've became aware that actually a lot of folks are using Discord as well, so I've created a server for the same purpose.
While we might not have an oscar-like ceremony, the winners were already announced today during a joint livestream on LiveOverflow's channel. During the stream we went through the 6 Top Games as well as through 4 Honorable Mentions we decided to award. You can see a recording at the bottom of the post or here on YouTube.
1.Sigma-18 by Krzysztof Jamróz (prize: 250 USD giftcard) 2.Space Hacker 3000 by Laila Los (200 USD giftcard) 3.Haxor2000 by Redssu (150 USD giftcard) 4.Conway haz life? by Kevin Fitch (125 USD giftcard) 5.spacewithoutx by Arenam (100 USD giftcard) 6.Init Player One by gamernissem, pigcowhybrid, icedeathblade (75 USD giftcard)
HM:Null Space by ognjenkatic (prize: 50 USD giftcard) HM:Grand Hackster by Mateusz Morszczyzna (prize: 50 USD giftcard) HM:Infestation by Drakir, Lowcase (prize: 50 USD giftcard) HM:Space Saver! by Thomas LEDOS (prize: 50 USD giftcard)
We will be contacting winners in the next few days about the prizes.
• The results will be announced tomorrow (Monday, 11th Feb 2019) 7pm CET during a joint livestream at LiveOverflow's channel: https://www.youtube.com/c/LiveOverflowCTF. After the livestream the results will also be posted on this blog in a separate blog post (edit: click).
Last year in November I gave a talk about why, in my personal opinion, there are so many vulnerabilities in C/C++ programs. The video from the English version of the talk went up a few days ago, so it's a good time to post the slides/video here.
Slides: click (Google Docs; use File→Download to get a PDF) Video: click (also embedded below)
Just a short archivist's note about the 2018 CTFtime.org season - it seems we (i.e. Dragon Sector) got the top score! The legendary Plaid Parliament of Pwning was close-second (one top-tier CTF difference basically), with another Polish team - p4 - taking the third place (congratz!).
The new (2019) season will start with Insomni'hack teaser CTF 2019. We actually have quite a streak with this CTF - we've won it 5 times in a row so far, so I guess we've set a starting bar quite high for us. Should be fun :).
In any case... for all the players that played 2018 or/and will play in 2019: GG, HF GL! See you soon :)
A few days ago astronomical winter started (at least in the northern hemisphere), so it's time for another constrained gamedev challenge - a game programming competition where the rules are made up (this time both by LiveOverflow and Gynvael Coldwind) and the limitations/constraints put in place are pretty challenging.
Therefore, welcome to the GWGC2018/19!
Submission deadline reached! Thank you for participation!
Newest rule update: 2019-01-31 (decided to accept submissions with trivial mistakes - see details below)
P.S. If you like this challenge, please help us spread the word around - there were 22 submissions last time, let's again aim at beating that record! :)
As some of you may know, I've written 1.08333 books in my native language - a 620 page book for intermediate / semi-advance programmers called something close to "Understanding Programming" or "To Understand Programming" (it was surprisingly well received and it even got an award from the Polish Information Processing Society), and a chapter in a reverse engineering book that had 12 authors (I've also served as a mix of a project manager and technical editor in this case). Anyway, for a long time I wanted to bring the first book to English, and I even got it translated to English and shown it to some publishers. However at that time I didn't really have the energy/time to follow up on it, and it was in great need of some serious editing.
In early 2018 I started thinking about the second edition of the book - what should I change? Update? Add? Or perhaps remove / move to an appendix? While there were several options, there was one thing I was sure about - I want to release both the Polish and English version at the same time.
This leads us to the main question: what software / technical stack do you recommend to write / edit a book in?
You might be familiar with "Missions" - usually short CTF-like/programming exercises posted sometimes at the end of my videos for the enjoyment of the viewers. Well, this time the mission is pretty special! Long story short, firemark (with help from foxtrot_charlie) prepared a battle bot competition for a clone of a classical game (Battle City / Tank 1990).
Dragon CTF 2018 main event took place last week at the Security PWNing Conference in Warsaw, Poland (you can find the final scoreboard in these twotweets). On my next livestream (this Wednesday 8pm CET) I'll go through a set of challenges from this CTF, all related to the Arcane Sector Online - an old-school-like (think: Ishar, Eye of Beholder, Dungeon Master) MMORPG game developed for the sole purpose of being hacked at during our competition.
I'll add that the game sources will be released soon, and that you'll be able to try to solve (most) the challenges yourselves as well.
The tournament will be held in a pretty standard jeopardy format, i.e. it's a team-based CTF with dynamic scoring, and several tasks that may be in one of the typical categories (web security, reverse engineering, cryptography, pwnables, etc). As it's a teaser CTF, the number of tasks will be pretty low and the CTF itself will only go for 24h.
There are prizes related to the main CTF event as well! The main Dragon CTF will take place during the Security PWNing Conference on 19-20 November in Warsaw, Poland, and will be open to conference participants and invited top teams from the teaser, and will have it's own set of prizes - the total prize pool for the main Dragon CTF is 17000 PLN!
The registration for the Teaser Dragon CTF 2018 is not yet open (it will be a few hours before the CTF). I'll update this post with details once we have the website online ;) UPDATE: The registration is now open - https://ctf.dragonsector.pl/ - and the CTF starts at 12pm UTC (2pm CEST) :)
Best of luck!
UPDATE 2: The CTF is now over! Good Game everyone!
See you at the main CTF*! * Please note that the "Teaser" was not a "Qualifier" - the Main offline CTF is open to all Security PWNing Conference attendees that are onsite.
This edition of Gynvael's Summer GameDev Challenge surpassed my expectations both in the number and in quality of submitted games. After publishing the set of constraints (language, resolution, colors, genre, etc) I thought that I went too far this time and that it will negatively influence the number of participants. But the authors proved me wrong - this edition almost doubled the number of submissions from half a year ago with 22 shooters delivered in total (you can play all of them here, though I still need to upload the source code / fix some formatting).
Actually every game, even the simplest ones, had something cool that caught my attention. Some of them had well designed mechanics, others were really shiny on the visual front with 3D graphics or cool lighting effect. A few had pretty good music or sound effects, or were just fun to play. It was really hard to pick the best ones.
But it the end, there can be only one.
Without further ado, the Winner, Runner-up, Third Place and Honorary Awards of GSGC 2018!
Submission deadline reached. You can see/play the games at http://gsgc2018.gynvael.tv/ (I'll add source codes in a few days). Expect winners to be announced next weekend (I need to play through all the qualifying games first! 22 submissions btw, you're amazing!)
For some reason it's summer in the northern hemisphere. This means it's time for another gamedev challenge - a game programming competition where the rules are made up (by me) and the limitations/constraints put in place are pretty challenging. And, as previously, there are rewards as well!
Without further ado, welcome to the GSGC2018!
P.S. If you like this challenge, please help me spread the word around - there were 13 submissions last time, let's aim at beating that record :)
As usual with this sort of competitions it was really hard to select the winner. Every submitted game had a thing or two that caught my eye and made it a worthy submission. Every submitted game had something special about it, be it a fun gameplay, aesthetic graphic design, or an overall polished feel to it. But it the end, there can be only one. Without further ado, the winners, runner-ups and third places of Gynvael's Winter GameDev Challenge:
PHP I/O functions support a handful of weird non-standard protocols and wrappers, with the most fun one probably being php://filter. I can recall at least several occasions where e.g. php://filter/resource=/some/file helped bypass a "remote URL only" restriction or php://filter/convert.base64-encode/resource=/some/file helped exfiltrate a binary file in an text-only or otherwise filtered (think: keyword blacklisting) output. When playing Insomni'hack teaser 2018 I discovered yet another trick, which surprised me to the extent that I couldn't believe my eyes that it actually worked. But to explain the trick, I'm actually going to have the explain the task.
Longer version: The goal of my Winter Challenge was for participants to create a tactical turn-based game in JavaScript that would fit within a 20KB limit and have the form of a single HTML file that works well on the most up to date version of Google Chrome on Microsoft Windows 10. I received 14 entries for the competition, two of which unfortunately didn't fully meet the criteria (one of which I still decided to showcase, but it won't be in the final ranking), which leaves 12 games to be considered for both Best Game Award (chosen by me) and Community Choice Award (chosen by you).
Community Choice Award Starting with the latter - to see and play the games please go to the following website: http://gwgc2017.gynvael.tv/
You can both read about the games there, as well as see a ~2 minute raw footage of each game and play the game yourself (look for the "Click here to play!" link).
Also, please vote! • To vote for a given entry please upvote a given video (i.e. click the 'thumbs up' button under the video on YouTube). • You can vote on all the entries you liked. • The deadline for voting is 23:59 CET on 28 Jan 2018 - at that time I'll do a snapshot of upvotes for all the videos and map that to 1st-3rd places of this award.
Best Game Award I'm still to grade the games (and perhaps ask various people for a second opinion - still to be decided) and I expect this to be a hard task as the games are pretty awesome.
I'll announce the winners of both categories near the end the month (i.e. between 29 and 31 of January).
That's about it for now. Please cast your vote(s) for the Community Choice Award - thanks!
Yesterday I've spent a fair amount of time trying to do a simple thing: in Python 3 write logs to a FIFO (created with mkfifo(1)) in a somewhat reliable way (i.e. without loosing logs on the writer end when the reader disconnects, nor duplicating them). It turned out to be quite an unforeseen adventure with what seems to be 3 levels of buffering on the way.
The exact scenario: 1. Both reader and writer connect to a FIFO. 2. Reader disconnects for some reason. 3. Writer writes N bytes of data and flushes it (and in the process gets a BrokenPipeError as expected). 4. Reader re-connects. 5. Writer does a flush (or disconnects, which implicitly invokes flush). 6. Reader reads data from the pipe (if any).
The main question here is: How many bytes (sent in the 3rd step) did the reader receive in the end?
Winter is upon us (well, at least where I live) and that seems to be a clear signal to make another gamedev challenge - a game programming competition where the rules are made up (by me) and the constraints put in place are pretty challenging. And there are rewards too!
Obligatory FAQ note: Sometimes I get asked questions, e.g. on IRC, via e-mail or during my livestreams. And sometimes I get asked the same question repeatedly. To save myself some time (*cough* and be able to give the same answer instead of conflicting ones *cough*) I decided to write up selected question and answer pairs in separate blog posts. Please remember that these answers are by no means authoritative - they are limited by my experience, my knowledge and my opinions on things. Do look in the comment section as well - a lot of smart people read my blog and might have a different, and likely better, answer to the same question. If you disagree or just have something to add - by all means, please do comment.
Q: How to learn reverse-engineering? Q: Could you recommend any resources for learning reverse-engineering? A: For the sake of this blog post I'll assume that the question is about reverse code engineering (RE for short), as I don't know anything about reverse hardware/chip engineering. My answer is also going to be pretty high-level, but I'll assume that the main subject of interest is x86 as that is the architecture one usually starts with. Please also note that this is not a reverse-engineering tutorial - it's a set of tips that are supposed to hint you what to learn first.
The results for Gynvael's Summer GameDev Challenge are in! You can find them below with an additional commentary for each game and category.
TL;DR: The results! Games From Scratch category 1. Space Logic Adventure (by Luke) 2. Untitled RTS (by mactec) 3. Space (by Seba) HM. The Fate of IsoGuy (by Piotr Krupa)
Games Created Using a Game Engine category 1. SpaceShooter (by GjM & mioot)
While the Gynvael's Summer GameDev Challenge 2017 results are not yet up (I'll announce them probably on Wednesday) I did review all the submitted games and created a 10-minute showcasing video with 1 minute dedicated for each game. You can find the video either on my channel on YouTube or simply down below.
Obligatory FAQ note: Sometimes I get asked questions, e.g. on IRC, via e-mail or during my livestreams. And sometimes I get asked the same question repeatedly. To save myself some time (*cough* and be able to give the same answer instead of conflicting ones *cough*) I decided to write up selected question and answer pairs in separate blog posts. Please remember that these answers are by no means authoritative - they are limited by my experience, my knowledge and my opinions on things. Do look in the comment section as well - a lot of smart people read my blog and might have a different, and likely better, answer to the same question. If you disagree or just have something to add - by all means, please do comment.
Q: How does one find vulnerabilities? A: I'll start by noting that this question is quite high-level - e.g. it doesn't reveal the technology of interest. More importantly, it's not clear whether we're discussing a system vulnerability (i.e. a configuration weakness or a known-but-unpatched bug in an installed service) that one usually looks for during a regular network-wide pentest, or if it's about discovering a previously unknown vulnerability in a an application, service, driver / kernel module, operating system, firmware, etc. Given that I'm more into vulnerability research than penetration testing I'll assume it's the latter. And also, the answer will be as high-level as the question, but should give one a general idea.
My personal pet theory is that there are three* main groups of methods (I'll go in more details below): * If I missed anything, please let me know in the comments; as said, it's just a pet theory (or actually a pet hypothesis).
1. Code review (this also includes code that had to be reverse-engineered). 2. Black box (this includes using automated tools like scanners, fuzzers, etc). 3. Documentation research.
All of the above methods have a set of requirements and limitations, and are good at one thing or the other. There is no "best method" that always works - it's more target specific I would say. Usually a combination of the above methods is used during a review of a target anyway.
As I mentioned in this post the last four livestreams on my YouTube channel were done by Artem "honorary_bot" Shishkin (github) and were on the quite anticipated and demanding topic of Windows kernel debugging with a healthy dose of both x86 from a system programming perspective, and an unexpected but very welcomed venture into the world of hypervisors. The series came to an end, therefore I would like again to thank Artem for both reaching out to me offering to do the streams and actually doing them in such a spectacular fashion - speaking for myself, I've learnt a lot!
All the videos are already uploaded on YouTube (links below), so in case you've missed them, nothing is lost (well, maybe for the ability to ask question, but I guess one can always reach out to Artem on Twitter). Please note that the links that Artem visited during the livestream are available for your convenience in each of the video descriptions on YouTube (if I missed anything please let me know).
• Windows Kernel Debugging - Part I, in which Artem shows how to configure your kernel debugging environment in several different ways, both including a virtual machine (with/without VirutalKD) and a second PC (controlled using Intel AMT and connected using various means, e.g. USB, Firewire or ethernet).
• Windows Kernel Debugging - Part III, in which Artem goes through the meanders of virtual memory and navigating through it using WinDbg. He also goes into the details of what's in a process and kernels virtual memory.
• Windows Kernel Debugging - Part IV, in which Artem showcases the physical memory and explains why a physical address is not always equal to RAM address, as well as ventures into the land of ACPI tables (if you're thinking about OSDev, you should check out this part regardless of whether you're interested in Windows kernel debugging or not). Artem also demos a hypervisor-level system debugger of his making.
While gamedev and coding challenges were something I've usually done on the Polish side of the mirror, I finally felt brave enough to try and invite all of my readers/viewers/visitors to participate. So, long story short, I would like to propose a month-long game development challenge - i.e. a kind of an informal (think: compo) competition where the participants (for example: you) try to create a game under a specific set of constraints written below.
It's a real pleasure for me to announce that the next four livestreams will feature Artem "honorary_bot" Shishkin (github), who will do an introduction into a long awaited topic of Windows Kernel Debugging. Artem, in his own words, is a fan of Windows RE, debugging and low-level stuff. He's been using WinDbg for kernel debugging for several years now for fun, customizing BSODs, building Windows kernel source tree or boot dependencies graph. Sometimes he might also accidentally discover such things as SMEP bypass on Windows 8 or how to disable PatchGuard in runtime. Being a great fan of Intel and specifically VMX technology he maintains his own bicycle debugger based on a bare metal hypervisor.
When: • 2017-08-02 (Wednesday), 8pm CET • 2017-08-03 (Thursday), 8pm CET • 2017-08-09 (Wednesday), 8pm CET • 2017-08-10 (Thursday), 8pm CET
How to not forget: • Subscribe to the YouTube channel and allow notifications. • Subscribe to Gynvael Hacking Livestreams calendar (also: ICS, calendar ID: pjta7kjkt1ssenq7fi9b6othfg@group.calendar.google.com).
Since I expect some technical problems (first time we'll be doing livestreaming with a guest in a remote location) I'll skip the usual news/announcements/mission solutions part of the streams to save some time (I'll probably do a dedicated stream for mission solutions later on). However DO expect new missions after each episode :)
At my last livestream, around 1:02:15, I tried to show an old (as in: 2006) GDB detection trick relying on the fact that GDB "leaked" two file descriptors into the child process, i.e. the child process was spawned having 5 descriptors already allocated instead of the default 3 (stdin/stdout/stderr or 0/1/2). So I've created a small program that opened a file (i.e. allocated the next available file descriptor) and printed the descriptor, compiled it and executed (without GDB) assuming that number 3 will be printed. Instead 5 showed up and left me staring in amazement wondering what just happened. Since investigating this wasn't really the topic of my livestream I ended there, but today I found a few minutes to investigate the mysterious file descriptors. As expected, in the end it turned out that it was a mix of my mistake and unexpected behaviours of other programs. Furthermore, the descriptors could be used to escalate privileges under some very specific and weird conditions. To sum up - it turned out to be a fun bug.
Recently on my Polish livestreams I've been writing a somewhat simple raytracer (see screenshot on the right; source code; test scene by ufukufuk), with the intention of talking a bit on optimization, multithreading, distributed rendering, etc. As expected, there were a multitude of bugs on the way, somemorevisual than others. My favorite one so far was a mysterious buffer overflow resulting with a C++ exception being thrown when rendering in 4K UHD (3840x2160) but not in 1080p (1920x1080). While trying to find the root cause I also run into a standard C library bug with the sqrt function (though it turned out not to be related in the end), which made the run even more entertaining.
Yesterday I've done a livestream during which I tried to learn the Blind Return Oriented Programming technique. Well, that isn't fully accurate - I already read the paper and had one attempt the evening before, so I knew that the ideas I wanted to try live should work. And they did, but only in part - I was able to find a signaling gadget (i.e. a gadget that sent some data to the socket) which could be used later on, as well as a "pop rsi; ret"-equivalent gadget (using a different method than described in the paper - it was partly accidental and heavily challenge specific). But throughout the rest of the livestream I was able to find neither a puts function nor use the gadget I already had to get a "pop rdi; ret"-equivalent gadget. The bug, as expected, was trivial.
Long story short (a more verbose version follows), my mistake was in the following code:
if err == "CRASH" and len(ret) > 0: return (err, ret)
The correct form is:
if err == "DISCONNECTED" and len(ret) > 0: return (err, ret)
And that's it. If you were on the YT chat or IRC you probably saw me "facepalming" (is that even a word? it should be) and pointing out the bug even before the stream went offline (i.e. during the mission screen). In the next 5 minutes I had both gadgets I needed, so that was the only bug there. Oh well.
Tomorrow (Wednesday, 22nd of March) at 8pm CET on my weekly Hacking Livestream I'll be joined by Michal 'carstein' Melewski to talk about creating plugins for Binary Ninja. Well, actually Michal will talk and show how to do it, and I'll play the role of the show's host. The plan for the episode is the following (kudos to carstein for writing this down):
1. Little intro to Binary Ninja - 5 minutes 2. Working with Binary Ninja API - console and headless processing - how to use console effectively - documentation
3. Basics of API - Binary view - Functions, - Basic Blocks - Instructions, - Low Level Intermediate Language (infinite tree)
4. Syscall problem, - first scan in console, - simple annotation (getting parameter value) - going back the instruction list - detecting same block?
5. Future of API and what can you do with it? - links to presentation (ripr, type confusion)
See you tomorrow!
P.S. We'll have a single personal Binary Ninja license to give away during the livestream, courtesy of Vector 35 folks (thanks!). Details will be revealed on the stream.
During the weekend I played 0CTF 2017 Quals - we finished 15th and therefore sadly didn't qualify. The CTF it self was pretty fun since the tasks had always a non-standard factor in them that forced you to explore new areas of a seemingly well known domain. In the end I solved 4 tasks myself (EasiestPrintf, char, complicated xss and UploadCenter) and put down write-ups for them during breaks I took at the CTF.
*** EasiestPrintf (pwn) http://blog.dragonsector.pl/2017/03/0ctf-2017-easiestprintf-pwn-150.html You've got printf(buf) followed by an exit(0), an unknown stack location and non-writable .got - this was was mostly about finding a way to get EIP control (and there were multiple ways to do it).
On the last episode of Hacking Livestream (#10: Medium-hard RE challenge - see below) I've shown how to approach a medium-hard reverse-engineering challenge. The example I used was the oxfoo1m3 challenge found in the "Level5-professional_problem_to_solve" directory of crackmes.de archive (this one), which I picked using such complex criteria as "something that runs on Ubuntu" and "something 32-bit so people with the free version of IDA can open it". As expected (and defensively mentioned several time during the stream), I was not able to complete this challenge during the livestream itself (which is only one hour, and that includes news and updates, and Q&A). However I did finish the task two days ago. It turned out I was close to the goal - took only around 30 minutes of additional work (which makes me wonder if Level5 is actually close to an RE300 challenge; probably it's closer to RE200). Anyway, here is the promised part 2 of the solution.
Note 1: While I'll write down a short recap of the initial steps and discoveries, please take a look at the recording of the episode #10 for details (crackme starts at 15m40s). If you've already seen it, just jump to part 2 in the second half of this post.
Note 2: Since this post is meant to have some education value I'll assume that the readers have only basic knowledge on RE techniques, and therefore I'll try to be verbose on some topics which are most likely well known amongst the more senior folks.
On yesterday's livestream (you can find the video here - Gynvael's Hacking Livestream #8) one viewer asked a really good question - while analyzing a rather large application, how to find the functions responsible for a certain functionality we are interested in? For an answer I've chosen to demonstrate the simple trace comparison trick I've seen years ago in paimei (a deprecated reverse-engineering framework), however my execution was done in GDB (though any other tracing engine might have been used; also, if you understand some Polish, I've pointed at this presentation by Robert Swięcki on last year's Security PWNing Conference in Warsaw). As expected the trick didn't yield the correct result when compared with another method I've shown (backtracking from a related string) and I kept wondering why.
The general idea behind the trick goes like this: you set up tracing (and recording), start the application, and then do everything except the thing you are actually interested in. Then, you run the application again (with tracing and recording), but now you try to do only the thing you are after, touching other functions of the application as little as possible. And in the end you compare the traces - whatever is on the second list, but is not on the first one, is probably what we've been looking for.
In case of GDB and temporary breakpoints (which are one-shot, i.e. they become disabled after the first hit) it's even easier, as you can do this in a single run, first exploring all/some/most of the non-interesting functions, and then hitting the exact function you need, which in turn will display temporary breakpoint hits for whatever remaining breakpoints were still set.
So my old Atari 800XL broke and I decided to fix it. Well, that's not the whole story though, so I'll start from the beginning: a long time ago I was a proud owner of an Atari 800XL. Time passed and I eventually moved to the PC, and the Atari was lent to distant relatives and stayed with them for several years. About 15 years later I got to play with my wife's old CPC 464 (see these posts: 1234 - the second one is probably the most crude way of dumping ROM/RAM you've ever seen) and thought that it would be pretty cool to check out the old 800XL as well. My parents picked it up from the relatives (I currently live in another country) and soon it reunited with me once again! Unfortunately (or actually, fortunately) technological development moved quite rapidly through the last 20 years so I found myself not having a TV I could connect the Atari too. And so I ordered an Atari Monitor → Composite Video cable somewhere and hid the Atari at the bottom of the wardrobe to only get back to it last week.
After connecting 800XL via Composite Video to my TV tuner card (WinFast PxTV1200 (XC2028)) it turned out that the Atari was alive (I actually thought it won't start at all due to old age), it boots correctly, but the video is "flickery":
So I decided to fix it. Now, the problem is I have absolutely no idea about electronic circuitry - my biggest achievement ever in this field was creating a joystick splitter for CPC 464 (though I am actually proud of myself to have predicted the ghosting problem and fixing it before soldering anything). Which means that this whole "I will fix the Atari" statement actually means "I will learn something about electronic circuits and probably break the Atari and it will never ever work again and I will cry" (though I hope to avoid the latter).
This blog post is the first of an unknown number of posts containing my notes of the process of attempting to fix my old computer. To be more precise, in this post I'm actually describing some things I've already did to try to pinpoint the problem (this includes dumping frames directly from GTIA - this was actually fun to do). Spoiler: I still have no idea what's wrong, but at least I know what actually works correctly.
So my first livestream in English took place yesterday evening (i.e. evening in my timezone) and it went rather smoothly - nothing crashed, broadcasting was not interrupted at any time and I even was able to go through both ReRe (Python RE 500) and EPZP (x86-64 Linux RE 50) challenges. The archived video is already up on YouTube (see also below) and what's left to do is ask about about your opinion: what do you think? Or, to be more precise, what do you think about stream quality, the content, the way I was presenting things (i.e. talking about what is happening, but sacrificing speed due to that), the chat, and so on? What topics would you like to hear about next (another CTF challenge or maybe something else)? Please use the comment section below - your opinion is welcomed!
The CONFidence Teaser CTF 2016 by Dragon Sector is now over and the results are in (congratz 9447!). Therefore I decided to share the sources of my task called ReRe, which was a Python rainbow-heavy obfuscation-heavy bytecode-all-around challenge. I won't spoil too much in case you would like to try to solve it (crackme/rere.py in the archive), but if you would like to read more on it, just see the SOLUTION.md file in the zip file. I'll add, that the obfuscation used self-modifying bytecode, some bytecode-level obfuscation and minor string obfuscation as well, so if you would like to learn more about Python 2.7 internal code representation, try your luck with ReRe :) It was solved 5 times btw.
Just a short note that the video from my talk "Python in a hacker's toolbox" (PyConPl'15) is already available on youtube. The slides can be found here.
A couple of hours ago I found myself, together with a couple of friends, locked in a small vault in a basement of an old tenement house in Wrocław/Poland. Objective: escape the room in 60 minutes (+ complete a side quest). To do this we had to look for clues, solve riddles, break codes (not unlike some crypto challenges I've seen on CTFs, though much simpler) and do quite a lot of creative thinking. In the end we failed (we were so close it's painful!). But we had A LOT of fun on the way anyway :). This kind of game is called "Live Escape Room" and the one we went to, which I strongly recommend, was the room "Vault" by Piwnica Quest.
(Collaborative post by Gynvael Coldwind and Mateusz “j00ru” Jurczyk) Just three days ago another edition of the great Insomni'hack conference held in Geneva came to an end. While the event was quite short, lasting for just one day, it featured three tracks of security talks, including some very interesting ones such as Automotive securityby Chris Valasek, or Copy & Pest – A case-study on the clipboard, blind trust and invisible cross-application XSS by Mario Heiderich. This year we were also invited to the conference to talk about CTF techniques, experiences and entertaining tasks encountered by the Dragon Sector team we lead and actively play in. We thus gave a presentation called Pwning (sometimes) with style – Dragons’ notes on CTFs, and are now making the slide deck publicly available for your enjoyment:
Just a quick note: the video from j00ru's and my talk from this year's CONFidence edition is now online. As mentioned in the previous post on the topic, the talk was called "On the battlefield with the Dragons" and consisted of a selection of interesting CTF task solutions with some useful tips and trick near the end.
Yesterday I had the pleasure to co-present with Ange Albertini (@angealbertini) - if you are into binary stuff, you probably know his website - corkami, which has all sorts of cool stuff, from posters detailing binary format (e.g PE 101) to binary polyglots, etc. We talked about "schizophrenic files", i.e. various file formats which get interpreted differently depending on what program you use (e.g. a BMP image which, when viewed in one viewer, shows a cat but when using a different one shows a flying shark). Basically the story goes that we both did (separately) some more or less random digging on (or more accurately in my case: randomly stumbling on) behaviors which allow one to create a file which is open to creative interpretation by the software, or (more commonly) parser authors just decide to not follow the specs or understand them in a different way; we decided to gather all this in one place and hence the talk. We presented it at Area41 in Zurich (which btw turned out to be really well organized and awesome conference). Slides and PoCs are available below.
Just yesterday another edition of the largest and most successful IT security conference held in Poland - CONFidence - ended. The Dragon Sector CTF team (which we founded and are running) actively participated in the organization of the event by hosting an onsite, individual CTF for the conference attendees and giving a talk about the most interesting challenges we have solved so far in our not too long CTF career.
Just to be clear, this post is not going to be about the float vs. float comparison. Instead, it will be about trying to compare a floating point value with an integer value in an accurate, precise way. It will also be about why just doing int_value == float_value in some languages (C, C++, PHP, and some other) doesn't give you the result you would expect - a problem which I recently stumbled on when trying to fix a certain library I was using.
Some time ago I decided to spend a few evenings playing with bug bounties. I've looked around and finally decided to focus on Prezi, since, being a user of their product, I was already somewhat familiar with it. As I seem to be naturally drawn to low-level areas, this quickly turned into an ActionScript reverse-engineering exercise with digging into the internals of SWF file format. I found a couple of interesting and fun bugs (e.g. an integer overflow that led to ActionScript code execution - you don't commonly see these this far from the C/C++ kingdom), and a few of them are worth sharing in my opinion.
As you probably know, we've run into some serious technical problems during the webinar (who would suspect a hangouts outage, huh), which caused both a 40 minute delay, changing the platform and some minor problems on the line (like lack of recording). So, as promised, I did record the talk again and I've just posted it on YouTube, to be enjoyed by everyone who couldn't see the live one, or decided to wait for the video for other reasons (the technical problems being a good one).
Next week I will be doing a free webinar on Reverse Engineering - "Data, data, data! I can't make bricks without clay."*. I will focus on practical RE tips and tricks I'm using day-to-day, which generally speed up the whole process or are simply cool (imo). The webinar will be hosted by Garage4Hackers as part of the Ranchoddas Series; see the details below.
As some of you may know, I've published a little over a hundred podcasts in my native language and it seems I finally got around to try and record something in English. The podcast is about one of the solutions (and a lazy one at that) to the "HackMe" Binathlon 400 task (it was basically a ZX Spectrum crackme) from the Olympic CTF Sochi 2014 run by the MSLC.
(Collaborative post by Mateusz “j00ru” Jurczyk and Gynvael Coldwind; a short version is available at the Google Online Security blog). Following more than two years of work, the day has finally came - the FFmpeg project has incorporated more than a thousand fixes to bugs (including some security issues) we have discovered in the project thus far:
$ git log | grep Jurczyk | grep -c Coldwind 1120
As this event clearly marks an important day in our ongoing fuzzing effort, we decided to provide you with some background on one of the activities we are currently working on.
Ange reminded me that I never published the English version of the slides from my "Ten Thousand Traps: ZIP, RAR, etc" talk. I gave the talk in May this year, in Krakow, on a small Polish conference called SEConference. Apart from the slides there are also several "weird" ZIP examples, including a "schizophrenic" (as Ange calles them - and it's an accurate and easy to remember name) abstract.zip, which seems to contain different files while viewing it under various ZIP parsers/libraries/unpackers (see slides 24 to 27 for results).
Some time ago I was reading a random Python JSON parsing library which was partly implemented in C. At one point I thought I spotted a bug in custom float number parsing - I've written a short PoC to trigger it and it worked (i.e. crashed Python), but behaved differently than I expected it to and seemed to work only on Windows. So I got back to looking at the code and in the end decided it was only my imagination - there was no bug. So… why did that PoC actually work? It turned out that in some cases the library fell back to using the good-old strtod for float parsing instead and yes, there was a bug - in the underlying msvcrt.dll strtod implementation.
(A shameless copy from j00ru's blog) This is a quick reminder that Gynvael and I (j00ru) are going to attend BlackHat US 2013 in Las Vegas next week with the “Bochspwn: Identifying 0-days via System-Wide Memory Access Pattern Analysis” presentation on the second day of the event. The talk is going to largely extend our previous performance at SyScan this year (see this blog post), detailing the implementation of our “Bochspwn” project, discussing other approaches to system-wide instrumentation and how it can be effectively used to discover different local vulnerability classes (not just double fetches!) in widely used kernels. We will also provide a follow up on using Bochspwn against open-source platforms (Linux, FreeBSD, OpenBSD), including extensive coverage of our findings there, and last but not least, we will release the Bochs instrumentation toolkit as an open-source project for everyone to hack on. If you happen to be in the Sin City at the time, don’t hesitate to come by and say hi! See you there!
In September last year I received a programming question regarding multi-level multiple same-base inheritance in C++, under one of my video tutorials on YouTube. I started playing with some tests and went a little too extreme for the likings of Microsoft 32-bit C/C++ Optimizing Compiler (aka Visual C++), which crashed while trying to compile some of the test cases. After some debugging, it turned out that it crashed on a rather nasty memory write operation, which could be potentially exploitable. Given that I was occupied with other work at the time, I decided to report it immediately to Microsoft with just a DoS proof of concept exploit. After 9 months the condition was confirmed to be exploitable and potentially useful in an attack against a build service, but was not considered a security vulnerability by Microsoft on the basis that only trusted parties should be allowed to access a build service, because such access enables one to run arbitrary code anyway (and the documentation has been updated to explicitly state this).
(Collaborative post by Mateusz "j00ru" Jurczyk and Gynvael Coldwind) It was six weeks ago when we first introduced our effort to locate and eliminate the so-called double fetch (e.g. time-of-check-to-time-of-use during user-land memory access) vulnerabilities in operating system kernels through CPU-level operating system instrumentation, a project code-named "Bochspwn" as a reference to the x86 emulator used (bochs: The Open Source IA-32 Emulation Project). In addition to discussing the instrumentation itself in both our SyScan 2013 presentation and the whitepaper we released shortly thereafter, we also went to some lengths trying to explain the different techniques which could be chained together in order to successfully and optimally exploit kernel race conditions, on the example of an extremely constrained win32k!SfnINOUTSTYLECHANGE (CVE-2013-1254) double fetch fixed by Microsoft in March 2013. The talk has yielded a few technical discussions involving a lot of smart guys, getting us to reconsider several aspects of race condition exploitation on x86, and resulting in plenty of new ideas and improvements to the techniques we originally came up with. In particular, we would like to thank Halvar Flake (@halvarflake) and Solar Designer (@solardiz) for their extremely insightful thoughts on the subject. While we decided against releasing another 70 page long LaTeX paper to cover the new material, this blog post is to provide you with a thorough follow-up on efficiently winning memory access race conditions on IA-32 and AMD64 CPUs, including all lessons learned during the recent weeks.
(Collaborative post by Mateusz “j00ru” Jurczyk and Gynvael Coldwind) Another week, another conference. Just a few days ago, Gynvael and I had the pleasure to attend and present at the CONFidence 2013 infosec conference traditionally held in Cracow, Poland. The event requires no further introduction - it has been simply the best Polish conference in the security area since it first started, and this year's edition was up to the usual high standard - we had some great time, meeting old and making new friends as well as enjoying some of the better talks.
(Collaborative post by Mateusz "j00ru" Jurczyk and Gynvael Coldwind) A few days ago we (j00ru and I) gave a talk during the SyScan'13 conference in the fine city of Singapore, and as promised (though with a slight delay), today we are publishing both the slide deck and a white paper discussing memory access pattern analysis - a technique we recently employed with success to discover around 50 double-fetch vulnerabilities in Windows kernel and related drivers (Elevation of Privileges and Denial of Service class; see Microsoft Security Bulletins MS13-016, MS13-017, MS13-031 and MS13-036 released in February this year. Also, stay tuned for more security patches in May and June).
(Collaborative post by Mateusz "j00ru" Jurczyk and Gynvael Coldwind) Almost five months ago, Gynvael Coldwind and Iwrote about an effort to improve the security of popular PDF parsing and rendering software; back then, we were primarily focused on the Chrome PDF Renderer and latest Adobe Reader applications. In order to achieve our results, we used several hundred CPU cores to create a unique, minimal set of PDF documents aimed at optimal code coverage. That corpus, which we now consider a fundamental part of our bug hunting success, was used as fuzzing input to numerous mutation algorithms (basic bitflipping, undisclosed PDF-specific algorithms that respect the primary rules of a document’s structure, and things in between).
The PHP equality operator == is (based on my experience) probably the weirdest and most overused comparison operator in popular programming languages. Looking back I had my attempts at trying to work out the details of it's innerworkings during various hackmes and CTFs, but I never got to the bottom of it (oh, if at this point you're wondering something along the lines of "Huh? What is he talking about? It's just a simple comparison operator, right?", you better keep reading). Anyways, the topic came back during a discussion on PHP security I had with my friend Claudio - we wondered if there is a good reference table for this operator. Well, during the last couple of days I had a little more time so I've decided to dig into the interpreter's code, make some tests, understand how the operator works and create such a reference table (might come in handy in the future CTFs). But this post is not only about the reference table - I've also noted down some interesting example which prove my point about == being weird - frankly, my current stance is that it shouldn't be used unless the developer knows EXACTLY what will happen in a given case.
I've published the newest version of NetSock, my simple C++ socket library (think TCP and UDP) for Windows and Linux, that's distributed under the terms of Apache License, Version 2.0. There aren't many changes (just one new function) so there is little need to upgrade (if anyone is actually using it).
(Bug found by Gynvael Coldwind, exploit developed by Mateusz “j00ru” Jurczyk) Several months back we have been playing with different file systems on various system platforms, examining the security posture and robustness of numerous device drivers’ implementations. One of the configurations we spent some time on was the commonly used NTFS on Microsoft Windows – as the file system is rather complex and still largely unexplored, we could expect its device driver to have some bugs to that would be easily uncovered. In addition, it was certainly tempting to be able to simply insert a USB stick, have it automatically mounted by the operating system and immediately compromise it by triggering a vulnerability in ntfs.sys. We had some promising results during the process, one being an interesting bug (though not quite dangerous) that we managed to analyze and exploit into a local elevation of privileges. In today’s post, we are providing some specifics regarding the nature of the vulnerability, and how it can be taken advantage of to acquire system privileges on the Microsoft Windows 7 64-bit platform.
Seems a new version - 0.8.2 - of cr-gpg (the GPG browser extension for Gmail for Chrome) was released today, so a brief note on a few bugs I reported in late August.
(Collaborative post by Gynvael Coldwind, Mateusz "j00ru" Jurczyk and Adam Iwaniuk) Friday, the 7th of September 2012 we were supposed to play the securitytraps.no-ip.org CTF. Unfortunately, the competition was postponed for a later date at the last moment, due to some significant technical problems. Next day evening we accidentally discovered another CTF taking place - the nullcon 2012 CTF, which sadly had already started one day earlier. Nonetheless, there were still 24 hours until the end, so we decided to give it a shot. TL;DR: We ended up 3rd (Team 41414141).
Several months ago, we started an internal Google Security Team effort to improve the general security posture of the Chrome embedded PDF reader, in an approach similar to the Flash fuzzing performed several months ago by Tavis Ormandy. During the course of a few weeks, we built a solid corpus of PDF documents that we feel gets significant coverage of the Chrome PDF Reader’s code base and used it to shake out more than 50 low-to-high severity bugs. All of the high and critical severity bugs we discovered have been fixed in the stable channel [1] [2] [3] as of this posting; see examples:
Sometimes it's fun to forget about why an Undefined Behavior in C is bad and just write some code that works here & now, but not necessarily will work tomorrow (with a different compiler version or different compiler settings) or in another place (another platform/system/architecture). A few weeks ago I had a chance to do such fun coding due to a thread "Hello world bez bibliotek i asm" (eng: "Hello world without libraries or asm") on a Polish programming forum - the thread creator was asking if it's possible to create a program writing out "Hello World" without using any libraries (including includes) or inline assembly. While at the beginning the thread was still about proper C, it soon moved to low-level code (still written as C) that depended on the underlying system, CPU architecture or even the way the compiler does its job. In this post I present my idea on how to write out "Hello World" to a GNU/Linux console; also it might be worth to take a look at the thread itself (I guess you won't need to know Polish just to look at C code ;>).
DLL shared sections have long been infamous for introducing security problems. A few months ago I decided to take a look if one can still find applications that use PE modules with shared sections in an insecure way (or using them at all). Today I'm releasing research notes, some tools and a demo of a Cygwin local privilege escalation (it's already fixed).
IGK is an annual game development conference in Poland and quite a fun one at that (not that I've been at many gamedev conferences). This year it started 29 of March and ended 1 of April in the evening (if counting the unofficial annual afterparty that is). The conference consists of a series of talks in the first two days and a 7 hours team gamedev compo. This year, as last year, I both had the opportunity to give a talk and to start in the compo, with quite decent results (for someone not really involved in game dev anymore).
Some time ago I've learned that you could connect two joysticks to the one-joystick-port CPC464 (you know, the old 8-bit computer I've already mentioned infewposts). So, I decided to practice my electronic skill, dig into the topic and make myself whatever piece of hardware is required to actually make two-joystick connection possible. Today I've finished the "1-to-2 joystick port splitter" and decided to document both the project, as well as the problems, the solutions, and the failures.
[Note: Collaborative post by Gynvael Coldwind and Mateusz "j00ru" Jurczyk] Five weeks ago, we have taken part in a fancy game-development competition aka Google GameJam 48h.As the name implies, the contest lasted for precisely two days; unfortunately, we were proven to lack supernatural powers and had to spend some of the precious time sleeping :) The theme of the event was “Magic versus Science”, and in our case, those two days of hardcore coding resulted in a 2D logic game called Magus Ex Machina. In the end, four teams in total managed to create and present games with actual gameplay; interestingly, we were the only ones making use of a native technology (i.e. OpenGL + SDL + a few other minor libraries), as the other competitors decided to go for pure browser (html + css + javascript) productions. Although we didn’t get the first place, we believe that the game is still fun to play, and thus worth sharing with a larger audience :)
Michal Zalewski's (who is better known as lcamtuf) new book went public a couple of hours ago. Since I was one of the lucky ones to get to see the book before it was published, I decided to write a short note on the book.
Recently I've stumbled on a review of a 1993 Amiga RPG game called Perihelion. I've never played this game (which I've heard is pretty good btw), but after looking at the screenshots I was amazed by what the authors could do with a 32-color limit - they created their palette out of two gradients: a gray one and an orange one. The effect is in my opinion awesome (screenshots below) - actually it's so cool that I've wrote a small program that converts a given image to exactly this 32-color palette (screenshots + source + win32 binary below as well) ;>
NetSock is a simple socket/networking lib/wrapper for C++ I've wrote back in 2007 (or 2006, actually not sure) and update from time to time. Even though I've been using it in random projects I'm releasing from time to time, I've never officially released it as a standalone project - an oversight I'm now going to correct.
A few years back, we've been (i.e. j00ru and Gynvael) working on a bootkit-related project (some polish SecDay'09 presentation slides can be found here: Bootkit vs Windows.pdf). One of its basic requirements was the ability to load custom boot-"sectors" from an external host in the local network. Since the publicly available solutions required too much time to be spent on configuration and we didn't need most of the offered functionality anyway, we decided to create an extremely simplified Preboot Execution Environment (PXE) server on our own, and so PiXiEServ came to be. Actually, a great majority of the source code was written by Gynvael, with only few modifications applied by me (i.e. j00ru).
The interesting difference between ASCII and Unicode is that the first had only one group of digits defined (30h to 39h), and the latter defines 42 decimal digit groups (I think it actually defines more, but nvm). A common programming language operation is to convert a sequence of digit-characters (yes, a number) to a machine-understandable integer. Does any default in-language string-to-integer support Unicode digits? Does any is-digit function return true on Unicode digits? Well, I did some checking and created a table (programming language/version/library vs digit group) that addresses these questions.
In march I've published some research related to Just another PHP LFI exploitation method that used the fact that the PHP engine stores (on disk) uploaded files (rfc1867) for a short period of time, even if scripts don't really expect them. The bottom line was that it's easy to exploit it on Windows, but on *nix it wasn't really possible unless some php script leaks certain information (temporary file name). Well, Brett Moore in his paper "LFI with phpinfo() assistance" pointed out that phpinfo() is the thing you want to look for on *nix.
For various reasons I've decided to take a deeper look at the evolving HTML 5 standard and related new HTTP extensions (or proposals of extensions). To tell you the truth, I was extremely surprised about the number of HTML tags that I didn't even hear of (like <ruby>, <kbd>, <meter>, <progress>, etc). Another thing that surprised me were a few security features I was not familiar with... so I decided to write down what I found interesting (so yes, this is a 'data dump' only).
I've never given too much thought to the problem of initialization of a local variable with static storage in C++ (and C). I just blindly assumed that the static variable works identically to a global variable, but is directly accessible (using language provided means) only in the block of code (and its child blocks) in which it was declared/defined. This is partly true - the big difference is that the global variable is initialized either at compilation time (constant/zeroed) or before the entry point, and the static variable is initialized either at compilation time (constant/zeroed) or when the execution first reaches it's declaration/definition. The interesting parts here are "how does the variable know if it has been initialized?", "can initialization fail and need to be rerun?", "what about concurrent multi-threading?" (the latter has some minor stability/security consequences). Let's take a look at GCC and Microsoft Visual C++ and how do they handle these issues...
Some time ago I had a crazy/funny idea for a local privilege escalation: run a privilege granting operation in an infinite loop and wait for a random bit flip in CPU/RAM that would make a 'can this user do this' check return 'true' instead of 'false'. Is this theoretically possible? Yes. And practically? Almost impossible, due to the unlikeliness of a bit flip and even more, the unlikeliness of a bit flip in the just right place. Nevertheless, I thought this idea was quite interesting and decided to dig into the topic. This post will summarize what I've found out and mention a few papers/posts might be worth reading.
A few years ago I would answer the above question with "because NULL is defined as a void pointer to 0", which is only half correct (and close to being wrong). The answer to this question is much more complicated and thus much more interesting.
Early Sunday morning discussion has resulted in j00ru coming up with an idea to mitigate some variants of kernel exploitation techniques by introducing a CPU feature that would disallow execution control transfers in kernel-mode to code residing in user memory area pages (e.g. addresses < 0x80000000 on a 32-bit Windows with default settings). The idea was that the system would mark every page as either being allowed to execute code in ring-0 or not. And hey, guess what... Intel has already proposed such a feature a month ago! Furthermore, it seems that this exact idea was already described in 2008 by Joanna Rutkowska, and two days ago she has published a follow up post on her blog.
A video recording of Unavowed's and mine lecture from Recon 2010 was published yestarday (about porting Syndicate Wars to modern OSes). You might (or might not ;>) find this interesting :)
A few days ago I had an interesting discussion with a friend (hi Felix ;>) about methods of exploiting Local File Inclusion bug in PHP. During it, an interesting idea came to my mind, about using temporary files created by the PHP engine while you send a packed with "attached" files (i.e. upload files) (please note that this is not the same as including an uploaded file ;>). I've decided to write a paper on this, but it later occurred that this method is actually known to some parties, but it seems it's not common knowledge (in opposition to e.g. including Apache logs or /proc/self/environ), so I decided to even the odds and publish the paper anyway.
1. Please remember that this post is 15 years old.
2. This isn't a good interview question for programmers, really.
3. While from programming / formal (C and C++ standards) perspective it doesn't make much sense to discuss what is the effective result of an UB (can be anything), it makes a lot of sense to discuss this in detail if you're coming from the offensive security perspective. After all, compilers are deterministic, and realistically the actual handling of an UB is preditable and falls into a limited set of potential outcomes.
Btw, if you enjoy this kinds of quirks, check out my two other projects:
→ hackArcana — where we have technical articles / challenges / workshops. → Paged Out! magazine — a free technical zine with 1 page articles about a lot of fun stuff in computer science.
With that, please enjoy this archival piece ↓
I've received the title riddle from furio and I found it interesting enough to pass it during the next few days to everyone that might be even remotely interested in C/C++ problems. The interesting thing here is the Undefined Behavior (UB), well... actually two UBs, thanks to which there are three possible correct answers: 11, 12 and 13.
After the CVE-2010-4398 (win32k.sys stack-based buffer overflow aka "UAC bypassing exploit" published on Code Project) was published a discussion appears on the net (at least on the Polish side of the net) whether the bug is exploitable on Windows XP. The problem on XP is that it has stack cookies (/GS cookies) which in this case were not present in other Windows versions. With j00ru we've looked into this issue, and found that the high entropy of the /GS cookies is questionable (at least in case of Windows drivers). Today, we publish the results of our research.
While discussing a few days ago a piece of code with aps, we've encountered some interesting (imho) differences in the implementation of atoi and [sf]scanf between different versions of msvcrt (Microsoft C-Runtime Library), glibc (GNU C Library) and the libc used on OSX. The said differences are observed when a number in the provided string cannot be represented as an integer, i.e. it's larger than INT_MAX (which is 0x7fffffff, or 2147483647 decimal) or smaller than INT_MIN (0x80000000, -2147483648 decimal).
When I came up with the idea of the 'Random' series, I've also created a separate "notepad" (in electronic form ofc), where I would note down things that I found interesting (a very subjective criteria as you see). The amount of noted became quite large, hence it's time to publish another Random-series post.
A few days ago I've received a piece of PHP 5 code, and got asked if it's OK. Basically, the code was validating user input, and was checking if only letters are used: both latin letters (A-Z) and additional Polish diacritized letters (i.e. Ą Ż Ś Ź Ę Ć Ń Ó Ł and lower version of these: ą ż ś ź ę ć ń ó ł). Additionally, there was a relatively small size limit to the input. And, as you might have already guessed, the code was not OK, and hence this post.
Yep, the fourth issue of the Hack In The Box Magazine is out! There is some cool stuff there, including a few reader chosen papers from previous issues.
Recently I'm working on some C++ code that (ab)uses many language features in a deep way, and hence, I found it necessary to do some digging to check if a given behavior is a result of standard fulfillment (i.e. it's defined in the language standard), defined compiler behavior (i.e. it's defined in the compiler (GCC in this case) documentation, but not necessarily in the language standard) or it's totally UB (i.e. it's not defined in any official documentation and cannot be relied on in any other version or compiler). So, this post is basically a data dump about some feature (preprocessor macro resolving to be exact) and probably seasoned programmers can skip it.
Well, this was supposed to be another "Random" post, but as the typing went on, it grew quite long, so I've decided to post this as a normal post. So, today's post will be about some new (i.e. new for me) extensions in GCC I've dig up, and a random rant on what I still miss in C/C++ (and no, I don't have templates of templates of templates in mind ;f).
Some time ago I've considered publishing brief posts with links to interesting (from my PoV) stuff, useful (again, from my PoV) tips&tricks, and other short stuff that doesn't really fill a fully-sized post. Finally, a week ago I've decided to test the idea in practice and made a test run on the Polish side of the mirror. Since it worked out quite well, so I decided to propagate the idea to this side of the mirror, and so, here it is ;>
Welcome back after a short break! The break was sponsored by relocating to another country, and so, by having to get the internet access installed at my new flat. Well, it's time for some random annoucements...
Yesterday I've received a photo from a friend, in JPEG format. The face of the person on the photo was concealed by a black rectangle. And that would be the end of the story, if my friend didn't notice that explorer on a preview of the photo shows the unconcealed face of the person in question :)
After this years CONFidence I came to conclusion that it would be fun to play with the old-school hardware/software solutions, like ANTIC, P/M, HAM6, etc. So, how to do that?
The videos from some CONFidence 2010 lectures have been published. Inter alia, the video from my and j00ru's lecture "Case study of recent Windows vulnerabilities" is available. The video is in a downloadable form (i.e. no online player is currently available).
Yesterday in the night we've published (on j00ru's blog) some old, low severity, PHP advisories (well, they are more research papers than actual advisories). Basically we've done the research to test a new (i.e. new for us) method of application review, which I find quite cool.
Looking through my directories I've found some tools that I've kept hidden in my desk, unpublished for some strange reasons. I'm thinking about finalizing the basic functionality of these, and finally putting them online. Anyways, one of such tools was HiperDrop - a simple command line process memory dumper for Windows.
The evening of 12 December 2006 I've written on my OpenRCE blog a post, in which I've explained that I'm looking for a job as a reverse engineer / programmer. After a few hours I've got an e-mail from Julio Canto, an employee of Spanish company called Hispasec, with an offer, that I've soon accepted. From that day over three years have passed and, quite surprisingly (and unexpectedly), it turns out that I will be leaving Hispasec the 19th day of August, to start with a new employer by the 6th of September. This post is kind of a summary of the period in which I've worked with Hispasec, and also, a way to say "thank you :)" to the great people who work there :)
Just a short (almost copy-pasted from j00ru's blog) post with the original advisories of the vulnerabilities we've talked about on CONFidence (and earlier on Hack In The Box Dubai), with slides used by as on the CONFidence conference. The advisories contain most of the technical details we've discussed during the lectures (and some time even more ;>).
Just a redirect-post for all you Windows researcher: Matthew has published a CSRSS opcode table on his blog - go and take a look - http://j00ru.vexillium.org/?p=349&lang=en :)
A few moments ago I've finished my talk at Hack In The Box in Dubai, on which I couldn't of course be in the flesh, since mr.Eyjafjallajökull canceled my flights, hence I've presented by phone and live desktop stream ;>. Below, you can download the slides, and also learn when the rest of the stuff (full advisories, videos, PoC exploits) will be released.
I've already written, in February, about the first vulnerability found by our team (that would be j00ru and me). Today, Microsoft has published reports about 5 more (well, there were 6 actually, but Microsoft decided to merge two into one, because of the way both of them could be fixed by the same change in the code) :)
About a month ago I've sent a CFP submission for the Hack In The Box 2010 Dubai conference, and yesterday I've officially got informed that my lecture was accepted! So, it looks like I'll be speaking in Dubai, 21th or 22th of April, about recent Windows vulnerabilities found by j00ru and me :)
Today is Exploit Wednesday, so it means that yesterday was Patch Tuesday. So, as every month, Microsoft published Microsoft Security Bulletin Summary (for February 2010) and a couple of patches. One of the vulnerabilities included in the summary (there are 25 altogether) was researched by j00ru and me (in this exact order - j00ru has found it, and we cooperated in researching the possibility of a successful exploitation) - it's the csrss.exe one, which could allow, inter alia, local privilege elevation or information disclosure.
As promised, It's time to reveal the technical story behind the Syndicate Wars Port. The story is divided into two parts - the first, and the second attempt to port this game. Comments are welcomed!
Syndicate Wars is a game published in 1996, created by Bullfrog. The game was written in C (Watcom) for the DOS4GWDOS extender. And of course it has stopped working natively (i.e. without emulators like DOSBox) when the modern operating systems, like GNU/Linux or Windows NT series, emerged. A few years ago my friend, Unavowed, told me about proposition of a project to create a port of Sydicate Word for modern OS'es like the two previous one I've mentioned. The port was to be done by decompiling the original executable file, locating all the functions from the standard C library, locating the DOS4GW and I/O (sound, keyboard, gfx, mouse, etc) dependencies, replacing them with modern native libc function call and libSDL/OpenAL libraries (sometimes using simple wrappers, other times by creating converters), and finally, recompiling it all to form native executables for the modern systems. Yesterday, we've (it was Unavowed who was the clear leader of this project) finished this project, and we've published executables, not only for GNU/Linux and Windows, but also for Mac OSX :)
A few weeks ago j00ru has visited me, and, as one can figure out, some more or less interesting ideas came to be. One of such ideas was to use the Call-Gate mechanism in kernel/driver exploit development on Windows, or, to be more precise, to use a write-what-where condition to convert a custom LDT entry into a Call-Gate (this can be done by modifying just one byte), and using the Call-Gate to elevate the code privilege from user-land to ring0. The idea was turned into some PoC exploits, and finally, into the paper presented below.
The Hack In The Box ezine, which was published in the years 2000-2005 (37 issues total) has been revived! The newest issue contains 6 articles (including mine), which gives 44 pages of text, in PDF (link below). Imho it's worth taking a look. It's very possible your find something interesting for yourself there :)
This post will be similar to the previous one, and will be about small, but interesting, details of x86 architecture, that might be (and sometimes are) easily overlooked by creators of emulators and virtual machines. The hero of today's post is the DR6 debug register, or, to be more precise, the four least significant bits of this register - B0 to B3 (breakpoint condition detected flags). Please read the whole post before jumping into any conclusions :)
In the last few days I've been playing with osdev again (last time I've coded something more than a boot menu (sorry, PL), was in 2003), so expect a few posts about assembler, x86 emulators and similar institutions. Today's post will be about the bswap reg16 instruction, running in protected mode - which, as one will find out, can be used, for example, to detect bochs or QEMU.
A few days ago my newest creation was published on the net - VirusTotal Uploader 2.0. Well, it is a different kind of tool that you're used to see from me - it has a window (it's not a console-app), it is well tested, and it is usable by a larger audience - this is mainly because I've created it under the Hispasec banner.
Below I present the download links for the slideshow (PDF) from my "Practical security in computer games" lecture, and a 0.0.1 alpha version of SilkProxy. A few more words about that last position: it's a multi-tunnel written in C++, scriptable in Python, that can be used for a few various things like protocol analysis, network traffic fuzzing or as a proxy/tunnel for some application. The version I publish is the version I've used while doing research for my lecture, and it's an alpha version - it means that not everything works as I would like it to work, the python API is undocumented, and some functionality is still (like replaying packets/network traffic and application-replay tunnel) missing - so, currently it might interest some curious programmers, but it's not yet usable for most of the researchers. However, I encourage you to take a look at it anyway (see the http.py script for a simple usage example; you run it by typing ./SilkProxy script.py, however the script is optional; to compile it you need to have Python installed with libs/headers, and GCC compiler (MinGW is OK)) ;>
Just a quick info. j00ru has published on his blog a syscall number/name table for the Win32k syscall shadow table (user32.dll, gdi32.dll and DirectX use it) - http://j00ru.vexillium.org/win32k_syscalls/ (it's very similar to the Metasploit one, however the one on the Metasploit page contains only kernel syscalls, and this one contains only win32k syscalls). If you like digging in the low level stuff, this is definitely something worth checking out!
About two days ago the net started to fill with information about a new programming language, created by people at Google. The language is called Go, and is something between a low-level language (like C/C++) and a high-level language (like Python, Java or C#), combining the features of the first (compiling to native code, execution speed, etc) and the later (garbage-collector, native thread support, etc). Yesterday evening I found some time to test the language, and I've managed to port one of my raytracers to Go. So, after the first sight, I decided to write a little about what I think of Go, and to show You my raytracer of course (source code at the end of the post). By the way, the opinion is made after only 5 hours of coding in Go, so I reserve the right to change my opinion at will, nd also, the things I write might not always be accurate ;>
Seems I'm a little behind on the English side of the mirror, so it's time to fix that with another PHP internals topic! This time I'll tell you the story of the PNG format, of course in the context of it's support in the getimagesize function.
And now for something completely different - my first laptop. It wasn't a Pentium as some might suspect. It wasn't even a 386. No, it was something, even older! If you are interested in computer archeology, you might be interested in this post ;>
Time has come to write the second part of the PHP getimagesize story (yes, that means that there was a first part *grin*). This time I'll focus more on what getimagesize is supposed to do - on acquiring the image sizes from different file formats. I'll also write about why you should NOT use getimagesize to validate if an uploaded file is really an image.
The getimagesize function is, in my humble opinion of course, one of the most interesting functions of the standard PHP library (yes, the standard library, even while it's documentation is placed among the GD extension functions). Why is it so interesting? Firstly, it's implementation is long, and as one knows, long code = many occasions to make minor or bigger mistakes. Secondly, the functions is commonly misused by php coders, introducing interesting bugs into the php code.
Today's post will be about something totally different. Mainly, I have a new SOHO router for a half of year or so at my place - yep, the D-Link DI-524 (rev.B), which replaced my old DI-604 (which I liked very much due to working correctly for a change ;p). And for the last half of year or so I couldn't play StarCraft 2v2 sitting with my ally on the same side of the router (LAN side that is). Until a few days ago...
(Be sure to checkout the demonstration video at the bottom of the page). Two months ago I've written about banker troyans, that some change DNS settings, other add a list of domains (used by financial institutions) to the c:\windows\system32\drivers\etc\hosts file. Of course both mentioned behaviors result in redirecting the user to some evil phishing site (sometimes an unlucky user might loose some money in effect).
Today I'll write about an interesting mistake (or misinterpretation in this case) I've spoted in my friends code, and also I'll mention a certain link I found in the referers. I'll start with the link...
It happened so that I got back to reversing banker trojans the other day, and celebrated it with a 24-hour marathon with many different foreign malware entities. Looks like that when I played with other stuff, the malware authors have also not slept! They thought of newer ways to make their malware more... weakly constructed ;p
Recently while reading some press news / blog posts, a few things came to my attention, which I would like to discuss (as in "rant about them") in this post.
The previous Sunday I decided to play a little with graphical interpretation of files again. Graphical interpretation, or visualizations as one may call it, is a large topic, there are even some interesting sites dedicated to that, in which the authors present colorful bitmaps representing files, that are commonly made moving file bytes directly to Red, Green and Blue channels. However, in my case, the bytes will not be mapped to RGB, instead, I choose to map them to X and Y.
At last! A technical post!.. in which, I'll describe the ESET crackme from this years edition of the CONFidence conference. The CONFidence crackme (made especially for the conference - it was NOT their old crackme that is available on the ESET website for some time now) is available for download below, so one can try to break it (it's a "recover the password" type of crackme) himself:
Time to update the English side of my mirror! As I've written before, I had the opportunity to be present at this years edition of the CONFidence conference, and, starting with a spoiler, I think it was the best conference I had attended so far :)
Welcome back after a short break! It looks like that after posting on the Polish side of the mirror about a binary I've received from a friend, the post was posted on wykop.pl - a Polish site like digg.pl. After that, the event chain was simple - many people have entered, too many requests for apache to handle, apache crashed, former (yep, I have change the blogs location) hosting admins decided that my blog causes too much trouble, so it went down. Additionally in that time I was on my way to the CONFidence 2009 conference, so I wasn't able to do anything about it ;(
Two days ago j00ru informed me that my cmd.exe add-on (the one that adds the ultra important feature - colors!) does not work on Windows 7 RC - so I decided to have a look, and so version 0.004d came into being!
Recently I've been working on a function written in assembly (NASM dialect) that was to be compiled and then loaded and executed at runtime by an Objective C application. The function was to search in a library image (in memory, MACH-O) for the address of a given method from a given class (using Objective C export sections), and it was composed of a 4 level loop. And, as one my figure, it didn't work as it should. At first, I tried to debug it by hand, but since it was a four level loop, with a ton of iterations, I soon gave up, and switched to a more automagical method - which I now describe to you (later I found out that the mechanics my function used are invalid, but thats a story for another day).
I'm sorry, but the slides are, again, in Polish (well, the source codes and demo videos don't have Polish in them, mostly because they don't have any text at all). I've been informed that a video from the lecture will available, so I'll take my time and attach English subtitles if anyone will be interested in it (let me know if you are interested).
The results of the GDPL compo have been posted (available also here). Seems my predictions were right and Krzysiek K. has won (he earned it ;>). Second was maskl ex aequo with me, and third came Reg. The full results are below:
Sunday, from 5pm till 8pm, another gamedev.pl compo took place. This time, it was a 3 hour compo during which one had to create a 'game that has both a cow and a pig' (a strange topic I must say). I don't have to much time recently, but I've figured that 3 hours is a period I can manage to find, especially Sunday. So, after I got a 'go' from my beloved wife, I took part in the March GDPL 3h Compo.
Finally has arrived the day when I take a look at creating OS X GUI applications! Applications on Mac are usually created using Objective C language (which I didn't have the pleasure to meet yet) and the Cocoa API (OS X equivalent of WinAPI; there was once also a Carbon API for Mac OS). From a programmers point of view, the Objective C syntax has really caught my eye - it's really very interesting! But I admit, from a reverse-engineers point of view Objective C gets* even better ;>
As my readers may know, for some time now I have access to a MacBook with OS X. Finally I found some time to test the standard exploiting techniques on OS X. I must admit that OS X surprised me positively once or even twice. However, this post is about another time, when the surprise was not positive in terms of security, additionally, it was kinda funny (in a hermetic way) ;>
The story starts as usual. I've been writing a certain application, that generates some test files. The files were very similar in structure, so I took the common factor out, and created a function that creates the common base of the file, and then, made a few functions that make modification to this base, and then the file is written (file shared, only in GF 15200 GTX! ;>). Of course, every modification function that I made, I had to add to a list of function in another part of the source file. And I've added each 'shader' function I created to that list. After 38th function I've grew tired of this...
In the previous post I've written about a tool that measures entropy, but, I left the problem of "why the hell should somebody measure entropy" for later. That "later" is now :)
There is a tool, created by j00ru and me, that I was supposed to publish online a long time ago. However, I judged that the code is not-pretty, and (one might add "as always") there was no time to prettify it. Until the previous weekend, when, while visiting my parents/brother, I opened the laptop and finally rewritten the code.
I've written lately about spam in the Referrer field of the HTTP header - bots insert links (some times with BBCode) to shops with viagra, penises, and enlarging your watches. Now it has evolved! The new wave of spam (that I observe on my blog for a few days now) has not one, but multiple links in the referrer field. At least one of these links is a subpage of my blog (anti-bot system evasion?), one leads to a shop with something, and sometime another one (or more) that has nothing to do with both appear. Just take a look:
Todays post will be contain some technical security stuff - I'll write about a technique called "return-oriented programming" or "return-oriented exploiting" or "ret-to-libc without returning to functions" or "ret-to-anything" (or by some other names as well). As always, I'll write about this technique from my point of view - meaning that, like always, I used this technique before reading any papers about it (it's related to my habit of reinventing the wheel).
Yesterday I've finally got some time to finish the changes in the new version of ExcpHook. So, version 0.0.5-rc2 (rc2 of alpha ;p) is ready for download, and might be even usable ;D
Todays post won't be about cmd.exe and BAT, for the moment, I have exhausted that topic. Instead, I'll write about drawing cool-looking "pictures" using sin and cos functions, in C++.
Long, long time ago, in the DOS times that is, one could configure the command prompt to be colorful, one could echo colorful messages, etc. And one could do all that thanks to the ANSI escape codes - short commands echoed to the "screen" (stdout/stderr that is) that caused the colors to change, the cursor to move, or the screen to be cleaned. ANSI escape code well working quite well in DOS, and they even worked in Windows 95/98. However, with the arrival of the NT family, the ANSI support in the console ceased to exist (well, it was still available in the command.com interpreter, but it's 16-bit running under NTVDM, what makes it not the best choice, not to mention that the NTVDM is not available in the 64-bit Windows versions). (A short offtopic: on *nix systems ANSI escape code well available almost always, and they are still available today).
Today's post will be, as promised, about OpenGL in .BAT scripts. At the very beginning, I would like to remind you (I was told that the correct form of 'you' is written with a lower 'y') that .BAT scripts have nothing to do with speed - they are just plain slow ;>
Finally You can download the official Windows 7 Beta release (unofficially You could do it for some time now). So I've downloaded it, installed it (looks cool), and started to play...
The night has ended, and so has the data transfer from CPC to PC (if interested, one can download the RAM dump here). I also rewritten the code from CPC to PC - the listing is at the end of this post.
Waiting for my new programmer (which will arrive "at the end of the week") I decided to dump RAM from my new Amstrad to my PC. But there was a problem - how to do it without having any cables to connect them, without floppies, etc? Well, I found a funny way to do it ;D
Frankly speaking it's good to have a wife. Especially a wife that finds an old (but operational) Amstrad-Schneider CPC 464 (64k Colour Peronal Computer) at the bottom of the wardrobe. And so, a new toy came into my possession (great! another architecture to play with ;D), and most definitely few random future posts will be about it.
In menu on the right (under the links to the posts) I've added a link to a section with some code snippets created now and then. They are rather simple, and I think beginner readers will be more interested in them, but I'll try to throw some more interesting stuff there later.
I've caught in my hands some malware, that had a very interesting idea about using one of Windows's entrypoint for making sure it would be run after a reboot.
The guys at Apple seem to like old tools. Last night we worked with Unavowed on some project (I'll write about it another time) - to be more accurate, we tried to to port the project to Mac OS X - and we've stumble on an obstacle. The obstacle told us it was called Apple Inc version cctools-698.1~1, GNU assembler version 1.38. And yes, that is the default assembler (as) used on the current Mac OS X, and I certainly hope that 1.38 is just a different version naming schema, since the current version (according to wiki) is 2.19, my MinGW says it uses 2.18.50, in the year 2000 version 2.11 was released, and in the current project changelog the oldest entry tells about version 1.93.01 - that would make 1.38 reaaaally old.
Few days ago two identical e-mails arrived at my mail box. Both with a job offer that smelled like dirty money laundry. The funny thing was the signature:
Sitting in my hotel room at the Polish edition of PyCON, I started to think what would happen, if a normal Windows process wipes out (almost) all of it's memory. By "wipe out" I mean to free/unmap what is possible (VirtualFree and UnmapViewOfFile), and overwrite with zeroes the rest. I've started to experiment with this, wanting to know how will the system, and other applications, react to this uncommon process condition. Below I describe the creation of a test application (I've found a few interesting (imho) problems), and a funny thing OllyDbg does while attaching to such a process.
About a half year ago I decided that I need an animated (as in "generated realtime") desktop wallpaper. I thought it should not use 3D acceleration (no OpenGL/D3D), the FPS should not be to high (2-3 frames per seconds were totally fine with me), and if possible, it should use more then one core (up to 4). I've started to write code, and, as always, didn't finish it. However, something does show on the screen, and imho it ain't all bad, so I decided to write a little on what is it, and how does it work - maybe someone will find it interesting ;> (the images are clickable, except the heightmap; the code for Windows/Mac/Linux and a short video is available at the bottom of the post).
Recently I've talked with my teammate oshogbo about the format bug (aka format string attack), and when we got to testing a sample code, a thing that should work - the %n tag, didn't work at all. What's more interesting, this behavior was Vista specific, since everything else worked well on XP. I've decided to take a look inside, and here's what I've found out...
Todays post will be an out of order one, and it will be dedicated to the function gettimeofday on the Windows system, or to be precise, the lack of this function.
Blah, I left the translation of the previous news from PL to EN for "tomorrow morning", and the "tomorrow morning" became "next week". But since the next week is here... let's talk about Sex baby^H^H^H^H^H^H^H^H SekIT 2008 (see my previous posts too).
It looks like that on 13th of October the first phase of this years Hacker Challenge starts - it's a tournament for RE organized by some unknown company from the USA. Well, I see that they cut down on the prizes this year, it must be the crisis. Anyway, since all the places in the tournament have some prize with it, I encourage REs to take part.
The new post is so late because I've got sucked in by C++ the previous Fridays night, and released Monday in the morning (with a few short breaks for sleeping, and another break which I used to go to the cinema to see Babylon A.D., which imho is a quite good and action packet movie, and it has a great dark climate, but the ending... well, it's easy to see that the studio has cut out 70 minutes of the movie, even when the director opposed... guess we'll just have to wait for the uncut directors version).
It's 3am, and I have some time to finally write about the next tasks at SD6. Well, but since it's 3am, and I'm a little tired, I'll just describe one task (that will be the task from the second day) for now (the rest will be described later). Btw, Polish speaking users can find the solutions on the official forum of SD6.
I still have a stupid cold, so most of the time I lie in bed trying to get better, hence another short news (I hope that tomorrow I can manage to write something more interesting for you guys).
In about two hours I'm leaving (with kanedaaa) to SekIT, a new polish security conference. On SekIT I'm going to give a speech, so I'll run on the scene and wave may hands, all to make the public happy (at least I hope so) ;> I'll talk about bankers - banking troyans. It will be a brief description of a few troyans, with some movies, and a lot of gesticulation. After SekIT I'll upload the slidesand movies, somewhere around here.
As one may know, yesterday at 8pm, the first day of the Internet phase of the Security Days 6 tournament began. The deadline for sending solutions to the first practical task was initially set to today, 9pm, but because of an attack on the main webpage of the tournament (a DDoS I was told) the deadline was changed to tomorrow 9pm. I'm not amused, since I wanted to post today some info about the first practical task, which imho was just about right for the first day - pretty easy, but still interesting. Well, I guess I'll write about it tomorrow ;>
Yesterday another method of making Google Chrome automatically download a file was posted on bugtraq. Of course an old discussion was restarted - is automatic file download a bug, feature, or a vulnerability?
A short info. Someone (Le Duc Anh - SVRT - Bkis) posted on the FD list about a Remote Buffer Overflow in Chrome, needing a little interaction from the user - the user needs to click 'Save as...' (the buffer overflow is related to the handling of the <title> while saving files). The researcher has provided two PoC exploits, one is said to run a calculator (on XP SP2, but it didn't work for me), and the other is just a DoS. It must be noted that that both the renderers and browser processes are crashed, so the vuln is located either in the browser, or is magically transfered from the renderer to the browser.
In the menu on the right a new entry called 'Projects' appeared. It will be a list of my projects, and it already contains one project with a description - a virtual machine created for a compo earlier this year.
Recently I was creating in C++ (MinGW g++) a small library for runtime-patching. A need came to create an assembler-only functions, without any additions from the compiler - a "naked" function. However, even if compilers from Redmond support __declspec(naked) attribute for the x86 [Visual C++ Language Reference - naked (C++)], GNU compilers don't - they only support "naked" in ports for ARM, AVR, IP2K and SPU [Using the GNU Compiler Collection (For GCC version 4.3.0) - Function Attributes]. The problem had several possible solutions:












![[...] representatives of this group of hackers, commonly referred to as 'ethical hackers', though theft and home invasion have nothing to do with ethics—but well, I understand, ethical hackers, because that's what they call themselves [...] (a certain Polish MP)](/img/quote-funny.png)





 As the old IT joke goes, in holiday season all IT workers visit their families to fix their computer. This time for me however it wasn't about fixing a computer, but copying contacts from an old Sony Ericsson (SE) Android phone to a new MaxCom* MM721 comfort phone. I'm not really sure what OS its running, but the whole idea behind that device is that it's supposed to be really simple to use, with the target audience being e.g. older people. And the MM721 indeed is simple to the extreme. Simple enough that moving ~200 contacts from the old phone to the new one proved to be an interesting (programming) challenge, mostly because I definitely didn't want to do it manually.
As the old IT joke goes, in holiday season all IT workers visit their families to fix their computer. This time for me however it wasn't about fixing a computer, but copying contacts from an old Sony Ericsson (SE) Android phone to a new MaxCom* MM721 comfort phone. I'm not really sure what OS its running, but the whole idea behind that device is that it's supposed to be really simple to use, with the target audience being e.g. older people. And the MM721 indeed is simple to the extreme. Simple enough that moving ~200 contacts from the old phone to the new one proved to be an interesting (programming) challenge, mostly because I definitely didn't want to do it manually.

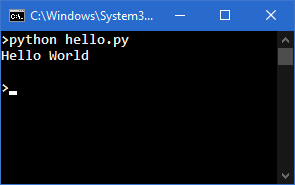

 While writing an article on how "Hello World" actually works in Python (written with j00ru and Adam Sawicki, and published in
While writing an article on how "Hello World" actually works in Python (written with j00ru and Adam Sawicki, and published in 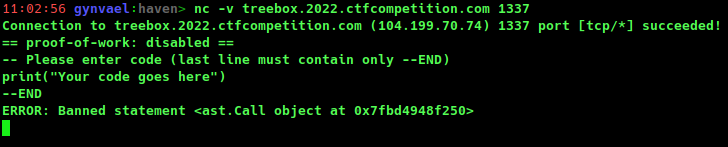










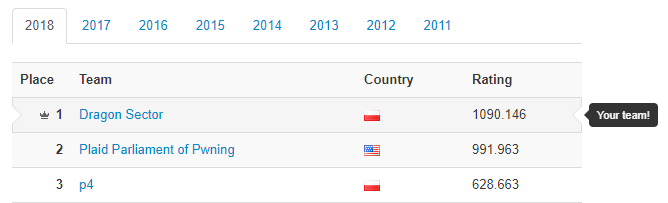
 As some of you may know, I've written 1.08333 books in my native language - a 620 page book for intermediate / semi-advance programmers called something close to "Understanding Programming" or "To Understand Programming" (it was surprisingly well received and it even got
As some of you may know, I've written 1.08333 books in my native language - a 620 page book for intermediate / semi-advance programmers called something close to "Understanding Programming" or "To Understand Programming" (it was surprisingly well received and it even got 






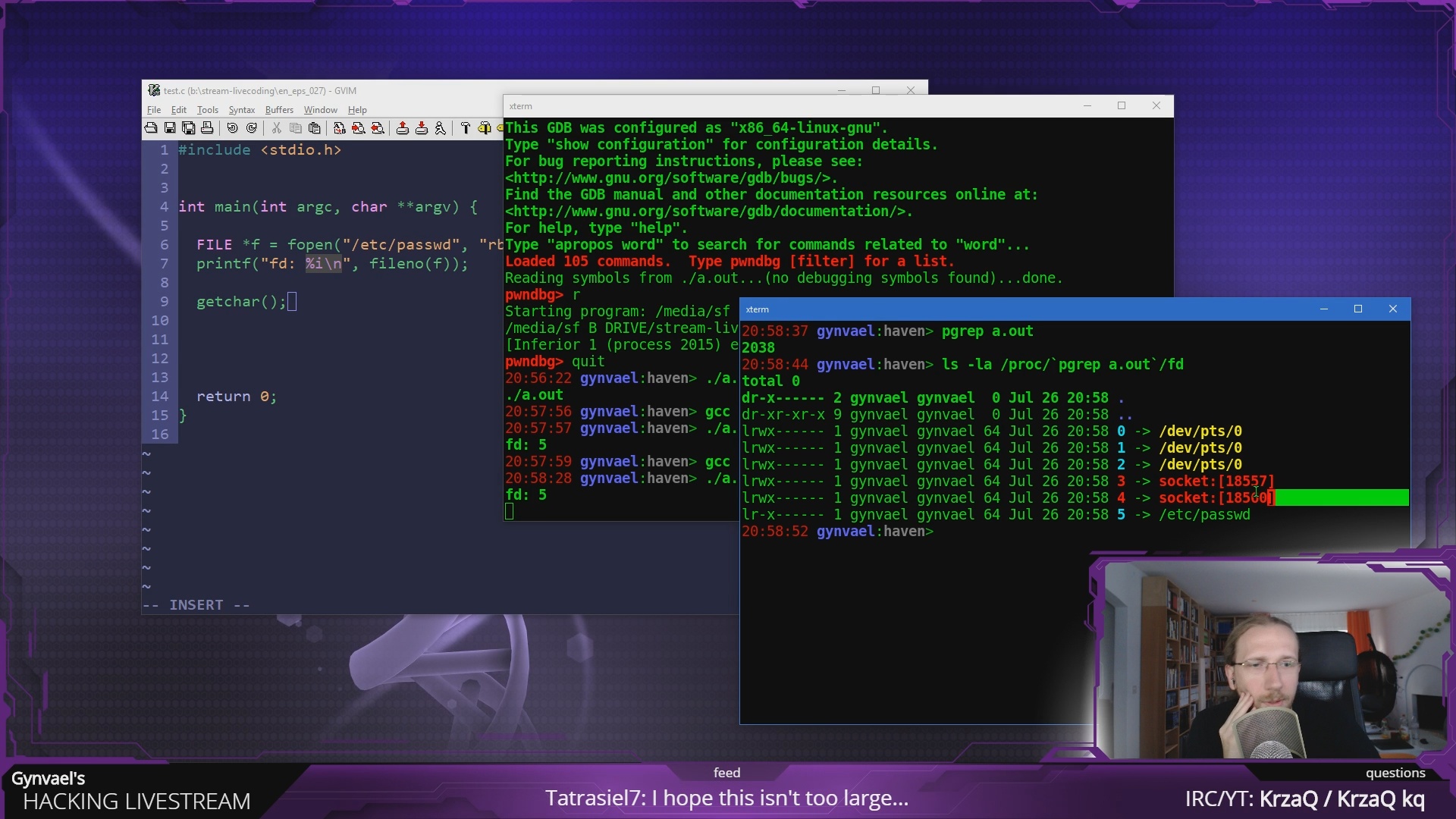

 So my old Atari 800XL broke and I decided to fix it. Well, that's not the whole story though, so I'll start from the beginning: a long time ago I was a proud owner of an Atari 800XL. Time passed and I eventually moved to the PC, and the Atari was lent to distant relatives and stayed with them for several years. About 15 years later I got to play with my wife's old CPC 464 (see these posts:
So my old Atari 800XL broke and I decided to fix it. Well, that's not the whole story though, so I'll start from the beginning: a long time ago I was a proud owner of an Atari 800XL. Time passed and I eventually moved to the PC, and the Atari was lent to distant relatives and stayed with them for several years. About 15 years later I got to play with my wife's old CPC 464 (see these posts: 
 Just a short note that the video from my talk "Python in a hacker's toolbox" (
Just a short note that the video from my talk "Python in a hacker's toolbox" (
 (Collaborative post by Gynvael Coldwind and
(Collaborative post by Gynvael Coldwind and  Yesterday I had the pleasure to co-present with Ange Albertini (
Yesterday I had the pleasure to co-present with Ange Albertini ( (A shameless
(A shameless 

 [Note: Collaborative post by
[Note: Collaborative post by 


 A few days ago my newest creation was published on the net - VirusTotal Uploader 2.0. Well, it is a different kind of tool that you're used to see from me - it has a window (it's not a console-app), it is well tested, and it is usable by a larger audience - this is mainly because I've created it under the Hispasec banner.
A few days ago my newest creation was published on the net - VirusTotal Uploader 2.0. Well, it is a different kind of tool that you're used to see from me - it has a window (it's not a console-app), it is well tested, and it is usable by a larger audience - this is mainly because I've created it under the Hispasec banner.

 Todays post won't be about cmd.exe and BAT, for the moment, I have exhausted that topic. Instead, I'll write about drawing cool-looking "pictures" using sin and cos functions, in C++.
Todays post won't be about cmd.exe and BAT, for the moment, I have exhausted that topic. Instead, I'll write about drawing cool-looking "pictures" using sin and cos functions, in C++.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}