





 Tematem czwartkowego livestreamu był system plików ext2, a konkretniej próba stworzenia w Pythonie parsera obrazu partycji sformatowanej jako ext2. Ostatecznie po niecałej godzinie pisania udało się poprawnie sparsować superblock i napisać trochę kodu, który miał listować aktywne inode'y, ale ten coś nie chciał działać. Nie chciałem wtedy specjalnie przedłużać streama, szczególnie, że moja wiedza na temat ext2 ograniczała się do fragmentu specyfikacji, który przeczytałem rano przed streamem; obiecałem więc dokończyć na spokojnie w ciągu kilku dni, co też udało mi się wczoraj zrobić.
Tematem czwartkowego livestreamu był system plików ext2, a konkretniej próba stworzenia w Pythonie parsera obrazu partycji sformatowanej jako ext2. Ostatecznie po niecałej godzinie pisania udało się poprawnie sparsować superblock i napisać trochę kodu, który miał listować aktywne inode'y, ale ten coś nie chciał działać. Nie chciałem wtedy specjalnie przedłużać streama, szczególnie, że moja wiedza na temat ext2 ograniczała się do fragmentu specyfikacji, który przeczytałem rano przed streamem; obiecałem więc dokończyć na spokojnie w ciągu kilku dni, co też udało mi się wczoraj zrobić.W skrócie, błąd sprowadził się do tego, że w niektórych miejscach (a w szczególności w polach bg_inode_bitmap oraz bg_inode_table deskryptora grupy bloków) numery bloków są podawane zaczynając od indeksu 1, a nie, jak założyłem, względem indeksu 0. Co więcej (i tutaj za bardzo dokumentacja nie pomagała) okazało się, że niektóre indeksy bloków (np. wskazane przed chwilą pola) są względne wobec początku grupy bloków, a w innych miejscach są to indeksy bezwzględne (tj. względne wobec początku partycji).
Po poprawieniu obu powyższych rzeczy listowanie inode'ów zaczęło (mniej więcej) działać, więc dopisałem jeszcze obsługę linków symbolicznych, katalogów i zrzucania zawartości plików. Ograniczyłem się natomiast tylko do obsługi bloków jawnie podanych w inode, tj. numery bloków podane niebezpośrednio (i_block, indeksy 12-14) zostały przeze mnie zignorowane. Co więcej, nadal kod ma jakieś problemy z inode'ami spoza pierwszej grupy, ale zawsze jest jakiś progres.
Finalny kod źródłowy można znaleźć na moim githubie: https://github.com/gynvael/stream/tree/master/031-ext2.
Poniżej wrzuciłem opis jeszcze kilku innych problemów i zmian w kodzie, które miały miejsce poza streamem.
inode 7
Podczas pracy nad powyższym kodem okazało się, że używana przeze mnie dokumentacja jest niekompletna w jeszcze jednym względzie - nie zawiera wszystkich obecnie stosowanych zarezerwowanych inode'ów, przez co spędziłem trochę czasu nad inode'em numer 7, który opisywał plik o wielkości 64 MB (gdzie cała partycja ma dokładnie tyle) i miał bardzo dziwnie wypełnioną tablicę bloków (tj. i_block).Ostatecznie okazało się, że inode numer 7 to EXT2_RESIZE_INO, specjalny inode przyspieszający powiększanie partycji (szybkie googlowanie znalazło też ten papierek z 2002 roku - "Online ext2 and ext3 Filesystem Resizing").
Powyższy inode, jak i kilka podobnych, skłoniły mnie do zrobienia blacklisty inode'ów:
# Skip special inodes.
if inode_nr in [
EXT2_BAD_INO,
EXT4_USR_QUOTA_INO,
EXT4_GRP_QUOTA_INO,
EXT2_BOOT_LOADER_INO,
EXT2_UNDEL_DIR_INO,
EXT2_RESIZE_INO,
EXT2_JOURNAL_INO,
EXT2_EXCLUDE_INO,
EXT4_REPLICA_INO,
]:
continue
Automagiczna mapa stałych do ich nazw
Pisząc obsługę katalogów chciałem wypisać tekstową nazwę określającą typ danego wpisu (np. "DIR" albo "SYMLINK"). Pole zawierające informacje o typie wpisu (file_type) jest typu liczbowego, więc zaszła potrzeba przetłumaczenia owej liczby na nazwę typu. Jest to oczywiście dość standardowy kawałek kodu, który de facto sprowadza się do stworzenia słownika, gdzie kluczami są liczby, a danymi tekstowe nazwy typów (ew. do funkcji ze switch-case'em w C/C++).Jakoś tak wyszło, że nie miałem ochoty pisać regexa, który by przerobił stałe z dokumentacji na słownik, więc ostatecznie podobny efekt uzyskałem za pomocą drobnego hacka (tj. kawałka kodu, który niekoniecznie powinien być używany w kodzie produkcyjnym). Zacząłem od skopiowania stałych do przestrzeni globalnej i powrzucania znaków = i # gdzie trzeba, co dało następujący fragment kodu:
EXT2_FT_UNKNOWN = 0 # Unknown File Type
EXT2_FT_REG_FILE = 1 # Regular File
EXT2_FT_DIR = 2 # Directory File
EXT2_FT_CHRDEV = 3 # Character Device
EXT2_FT_BLKDEV = 4 # Block Device
EXT2_FT_FIFO = 5 # Buffer File
EXT2_FT_SOCK = 6 # Socket File
EXT2_FT_SYMLINK = 7 # Symbolic Link
A następnie skorzystałem z następującego one-linera (dla czytelności rozbitego na trzy linie):
FT_TO_STR = dict(
[(y, x) for x, y in globals().items()
if "EXT2_FT_" in x])
Powyższy kod działa w następujący sposób: ze słownika zmiennych globalnych wybierane są wszystkie klucze, które mają string "EXT2_FT_" w swojej nazwie, a następnie jest robiona z nich lista krotek (tupli) w postaci (tekstowy klucz, liczba), a ta z kolei jest konwertowana do słownika (pierwszy element krotki jest używany jako klucz, a drugi jako dane pod danym kluczem).
Zapewne napisanie regexa trwałoby krócej. Oh well.
EDIT: D0han mi właśnie uświadomił, że dicty też można tworzyć w podobny sposób jak listy/iteratory, tj. można było powyższe skrócić do:
FT_TO_STR = {y: x for x, y in globals().items() if "EXT2_FT_" in x}TIL :)
DictWrapper
Już podczas streama wspominałem, że mógłbym obudować słownik tak by z jego kluczy można korzystać za pomocą notacji używanej przy atrybutach (polach) obiektów (tj. tak, by zamiast pisać superblock["nazwa_pola"] można równie dobrze napisać superblock.nazwa_pola). W tym celu zrobiłem dość prostą klasę, która w konstruktorze przyjmuje słownik, oraz definiuje specjalną metodę __getattr__ która, jeśli istnieje, jest wywoływana w momencie odwołań (do odczytu) do pól obiektu. W tej metodzie wystarczyło pobrać dane z podanego klucza (pola) ze słownika, i ew. wyemulować odpowiedni wyjątek w razie braku pola (choć to nie było specjalnie konieczne w tym wypadku).class DictWrapper:
def __init__(self, d):
self._d = d
def __getattr__(self, name):
try:
return getattr(self._d, name)
except AttributeError:
pass
try:
return self._d[name]
except KeyError as e:
raise AttributeError("'%s' object has no attribute '%s'" % (
type(self).__name__, e.message
))
Po dodaniu powyższej klasy zmodyfikowałem lekko parse_from_description tak, by zamiast słownika zwracała obiekt DictWrapper oparty o wcześniej zwracany obiekt.
Linki symboliczne
Krótką ciekawostką jest to, że linki symboliczne (tj. EXT2_S_IFLNK) mogą mieć dane (tj. ścieżkę, na którą wskazują) zapisane w samym inode (w miejscu pola i_block), ale tylko jeśli długość ścieżki nie przekracza 60 bajtów.HexII
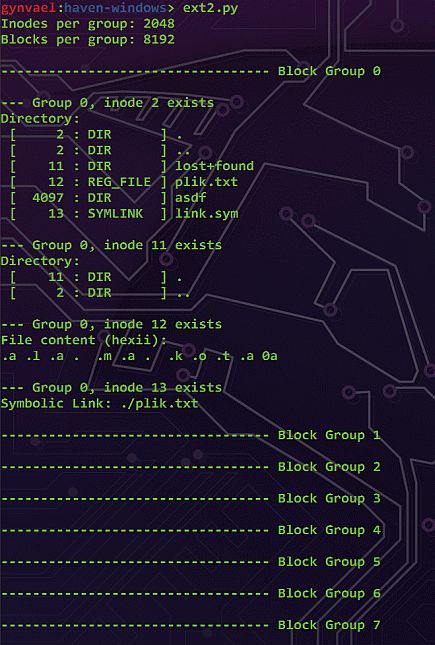
Jak było widać na ilustracji wyżej, samą zawartość pliku postanowiłem przedstawić w notacji HexII:File content (hexii):
.a .l .a . .m .a . .k .o .t .a 0a
Notacja ta została wymyślona przez Ange Albertiniego i jest próba sprawienia, by notacja heksadecymalna była trochę bardziej czytelna. Więcej o HexII można poczytać np. tutaj.
{kind=link}
Python 2 i dziedziczenie po object
Podczas streama została mi zwrócona uwaga, że moja klasa powinna dziedziczyć po object, na co odparłem coś w stylu, że to w zasadzie bez różnicy / samo się zrobi niejawnie. Po streamie D0han zwrócił mi uwagę, że jednak jest trochę różnic i nie zrobi się automatycznie, więc rzuciłem okiem o co z tym chodzi.<+D0han> Gynvael: brak dziedziczenia klasy po object w pythonie 2 nie jest bez znaczenia ;(
W dużym skrócie, Python 2 posiada dwa "rodzaje" klas - starsze (która została usunięta w Python 3), oraz nowsze, która m.in. pozwalają na prześledzenie drzewka rodzinnego (tj. grafu dziedziczenia), mają więcej wbudowanych metod i pól itd.
Poniżej znajduje się przykładowy kod przechodzący po całym drzewie domyślnie dostępnych klas:
def walk(c, level=0):
print " " * level, c
s = None
try:
s = c.__subclasses__()
except TypeError:
return
for subclass in s:
walk(subclass, level + 1)
class C(object):
pass
walk(C.__base__) # Ew. walk(object)
Wynik działania jest dość długi, więc umieściłem go w osobnym pliku tekstowym. Dodam, że dokładnie z tej cechy korzysta się czasem przy wyskakiwaniu z sandboxów pythonowych.
Więcej o różnicach między oboma stylami klas można poczytać np. tutaj lub tutaj
I w zasadzie tyle na dzisiaj. W planach na najbliższe dni mam jeszcze jeden post (o exploitacji jitbf), a poza tym do zobaczenia w środę i czwartek na cotygodniowych livestreamach :)
Comments:
"napisać span style="font-family:monospace">superblock.nazwa_pola)" zabrakło < i znacznika zamykającego span, no chyba, że tak to ma wyglądać :D
Thx, naprawione :)
Add a comment: