






Q: How to learn reverse-engineering?
Q: Could you recommend any resources for learning reverse-engineering?
A: For the sake of this blog post I'll assume that the question is about reverse code engineering (RE for short), as I don't know anything about reverse hardware/chip engineering. My answer is also going to be pretty high-level, but I'll assume that the main subject of interest is x86 as that is the architecture one usually starts with. Please also note that this is not a reverse-engineering tutorial - it's a set of tips that are supposed to hint you what to learn first.
I'll start by noting two crucial things:
1. RE is best learnt by practice. One does not learn RE by reading about it or watching tutorials - these are valuable additions and allow you to pick up tricks, tools and the general workflow, but should not be the core of any learning process.
2. RE takes time. A lot of time. Please prepare yourself for reverse-engineering sessions which will takes multiple (or even tens of) hours to finish. This is normal - don't be afraid to dedicate the required time.
While reverse-engineering a given target one usually uses a combination of three means:
• Analysis of the dead-listing - i.e. analyzing the result of the disassembly of a binary file, commonly known as static analysis.
• Debugging the live target - i.e. using a debugger on a running process, commonly known as dynamic analysis.
• Behavioral analysis - i.e. using high-level tools to get selected signals on what the process is doing; examples might be strace or Process Monitor.
Given the above, a high-level advice would be to learn a mix of the means listed above while working through a series of reverse-engineering challenges (e.g. crackmes or CTF RE tasks1).
1 While reversing a crackme/CTF task is slightly different than a normal application, the former will teach you a lot of anti-RE tricks you might find and how to deal with them. Normal applications however are usually larger and it's easier to get lost in the huge code base at the beginning.
Below, in sections detailing the techniques mentioned above, I've listed resources and tools that one might want to get familiar with when just starting. Please note that these are just examples and other (similar) tools might be better suited for a given person - I encourage you to experiment with different programs and see what you like best.
Analysis of the dead-listing
Time to call out the elephant in the room - yes, you will have to learn x86 assembly. There isn't a specific tutorial or course I would recommend (please check out the comment section though), however I would suggest starting with 64-bit or 32-bit x86 assembly. Do not start with 16-bit DOS/real-mode stuff - things are different in 64-/32-bit modes (plus 64-/32-bit modes are easier in user-land2) and 16-bit is not used almost anywhere in modern applications. Of course if you are curious about the old times and care about things like DOS or BIOS, then by all means, learn 16-bit assembly at some point - just not as the first variation.
2 16-bit assembly has a really weird addressing mode which has been replaced in 64-/32-bit mode with a different, more intuitive model; another change is related to increasing the number of possible address encodings in opcodes, which make things easier when writing assembly.
When learning assembly try two things:
• See how your C/C++ compiler translates high-level code into assembly. While almost all compilers have an option to generate output in assembly (instead of machine code wrapped in object files), I would like to recommend the Compiler Explorer (aka godbolt.org) project for this purpose - it's an easy to use online service that automates this process.
• Try writing some assembly code from scratch. It might be a pain to find a tutorial / book for your architecture + operating system + assembler (i.e. assembly compiler) of choice3 and later to actually compile and link the created code, but it's a skill one needs to learn. Once successfully completed the exercise with one set of tools, try the same with a different assembler/linker (assembly dialects vary a little, or a little more if we point at Intel vs AT&T syntax issue - try to get familiar with such small variations to not get surprised by them). I would recommend trying out the following combinations:
• Linux 32-/64-bits and GNU Assembler (Intel, AT&T, or both),
• Windows 32-/64-bits and fasm,
• Linux 32-/64-bits and nasm + GCC.
3 A common mistake is to try to learn assembly from e.g. a 16-bit + DOS + tasm tutorial while using e.g. 32-bit + Linux + nasm - this just won't work. Be sure that you use a tutorial matched to your architecture + operating system + assembler (these three things), otherwise you'll run into unexpected problems.
One thing to remember while learning assembly is that it's a really really simple language on syntax level, but the complexity comes with having to remember various implicit details related to the ABI (Application Binary Interface), the OS and the architecture. Assembly is actually pretty easy once you get the general idea, so don't be scared by it.
A couple of supporting links:
• The Complete Pentium Instruction Set Table (32 Bit Addressing Mode Only) by Sang Cho - a cheatsheet of 32-bit x86 instructions and their machine-code encoding; really handy at times.
• Intel® 64 and IA-32 Architectures Software Developer Manuals - Volume 2 (detailed description of the instructions) is something you want to keep close and learn how to use it really well. I would recommend going through Volume 1 when learning, and Volume 3 at intermediate/advance level.
• AMD's Developer Guides, Manuals & ISA Documents - similar manuals, but from AMD; some people prefere these.
• [Please look in the comment section for any additional links recommended by others.]
One way of learning assembly I didn't mention so far, but which is really obvious in the context of this post, is learning by reading it, i.e. by reverse engineering code4.
4 Do remember however that reading the code will not teach you how to write it. These are related but still separate skills. Please also note that in order to be able to modify the behavior of an application you do have to be able to write small assembly snippets (i.e. patches).
To do that one usually needs a disassembler, ideally an interactive one (that allows you to comment, modify the annotations, display the code in graph form, etc):
• Most professionals use IDA Pro, a rather expensive but powerful interactive disassembler, that has a free version (for non-commercial use) that's pretty limited, but works just fine for 64-bit (and some 32-bit) x86 Windows (PE), Linux (ELF) and OSX (Mach-O) targets (technically there seems to be 16-bit x86 support too, but without MZ file support).
• The new player on the market is Binary Ninja, which is much cheaper, but still might be on the expensive side for hobbyists.
• Another one is called
• There is also an open source solution in the form of radare2 - it's pretty powerful and free, but has the usual UX problems of open-source software (i.e. the learning curve for the tool itself is much steeper).
• If all else fails, one can always default to non-interactive disassembler such as objdump from GNU binutils that supports architectures that even IDA doesn't (note that in such case you can always save the output in a text file and then add comments there - this is also a good fallback when IDA/BN/etc don't support a given architecture of interest).
Having the tool of choice installed and already knowing some assembly it's good to just jump straight into reverse-engineering of small and simple targets.
A good exercise is to write a program in C/C++ and compile it, and then just having the disassembler output trying to reverse it into a high-level representation, and finally into proper C/C++ code (see the illustration below).

Once you get a hang of this process you should also be able to skip it altogether and still be able to understand what a given function does just after analyzing it and putting some comments here and there (keep in mind that this does take some practice).
By the way...
If want to improve your binary file and protocol skills, check out the workshop I'll be running between April and June → Mastering Binary Files and Protocols: The Complete Journey
One important thing I have not yet mentioned is that being able to reverse a given function only gives you a low-level per-function view of the application. Usually to understand an application you need to first find which functions is it worth to analyze at all. For example, you probably don't want to get sidetracked by spending a few hours reversing a set of related functions just to find out they are actually the implementation of malloc or std::cout (well, you'll reverse your share of these anyway while learning, that's just how it is). There are a few tips I can give you here:
• Find the main function and start the analysis from there.
• Look at the strings and imported functions; find where they are used and go up the call-stack from there.
• More advance reversers also like to do trace diffing in case of larger apps, though this FAQ isn't a place to discuss this technique.
Debugging the live target
Needless to say that a debugger is a pretty important tool - it allows you to stop execution of a process at any given point and analyze the memory state, the registers and the general process environment - these elements provide valuable hints towards the understanding the code you're looking at. For example, it's much easier to understand what a function does if you can pause its execution at any given moment and take a look what exactly does the state consist of; sometimes you can just take an educated guess (see also the illustration below).
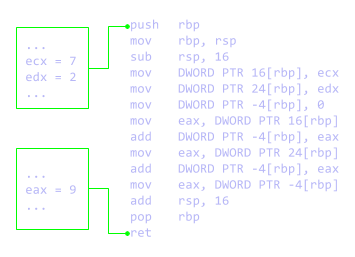
Of course the assembly language mentioned in the previous section comes into play here as well - one of the main views of a debugger is the instruction list nearby the instruction pointer.
There is a pretty good choice of assembly-level debuggers out there, though most of them are for Windows for some reason5:
• x64dbg - an open-source Windows debugger similar in UX to the classic OllyDbg. This would be my recommendation for the first steps in RE; you can find it here.
• Microsoft WinDbg - a free and very powerful user-land and kernel-land debugger for Windows made by Microsoft. The learning curve is pretty steep as it's basically a command-line tool with only some features available as separate UI widgets. It's available as part of Windows SDK. On a sidenote, honorary_bot did a series of livestreams about WinDbg - it was in context of kernel debugging, but you still can pick up some basics there (1, 2, 3, 4; at first start with the 2nd part).
• GDB - the GNU Debugger is a powerful open-source command-line tool, which does require you to memorize a set of commands in order to be able to use it. That said, there are a couple of scripts that make life easier, e.g. pwndbg. You can find GDB for both Linux and Windows (e.g. as part of MinGW-w64 packet), and other platforms; this includes non-x86 architectures.
• [Some interactive disassemblers also have debugging capabilities.]
• [Do check out the comment section for other recommendations.]
5 The reason is pretty obvious - Windows is the most popular closed-source platform, therefore Windows branch of reverse-engineering is the most developed one.
The basic step after installing a debugger is getting to know it, therefore I would recommend:
• walking through the UI with a tutorial,
• and also seeing how someone familiar with the debugger is using it.
YouTube and similar sites seem to be a good starting point to look for these.
After spending some time getting familiar with the debugger and attempting to solve a couple of crackmes I would recommend learning how a debugger works internally, initially focussing on the different forms of breakpoints and how are they technically implemented (e.g. software breakpoints, hardware breakpoints, memory breakpoints, and so on). This gives you the basis to understand how certain anti-RE tricks work and how to bypass them.
Further learning milestones include getting familiar with various debugger plugins and also learning how to use a scripting language to automate tasks (writing ad-hoc scripts is a useful skill).
Behavioral analysis
The last group of methods is related to monitoring how a given target interacts with the environment - mainly the operating system and various resources like files, sockets, pipes, register and so on. This gives you high-level information on what to expect from the application, and at times also some lower-level hints (e.g. instruction pointer when a given event happened or a call stack).
At start I would recommend taking a look at the following tools:
• Process Monitor is a free Windows application that allows you to monitor system-wide (with a convenient filtering options) access to files, register, network, as well as process-related events.
• Process Hacker and Process Explorer are two free replacements for Windows' Task Manager - both offer more details information about a running process though.
• Wireshark is a cross-platform network sniffer - pretty handy when reversing a network-oriented target. You might also want to check out Message Analyzer for Windows.
• strace is a Linux tool for monitoring syscall access of a given process (or tree of processes). It's extremely useful at times.
• ltrace is similar to strace, however it monitors dynamic library calls instead of syscalls.
• [On Windows you might also want to search for a "WinAPI monitor", i.e. a similar tool to ltrace (I'm not sure which tool to recommend here though).]
• [Some sandboxing tools for Windows also might give you behavioural logs for an application (but again, I'm not sure which tool to recommend).]
• [Do check out the comment section for other recommendations.]
The list above barely scratches the surface of existing monitoring tools. A good habit to have is to search if a monitoring tool exists for the given resource you want to monitor.
Other useful resources and closing words
As I mentioned at the beginning, this post is only supposed to get you started, therefore everything mentioned above is just the tip of the proverbial iceberg (though now you should at least know where the iceberg is located). Needless to say that there are countless things I have not mentioned here, e.g. the whole executable packing/unpacking problems and other anti-RE & anti-anti-RE struggles, etc. But you'll meet them soon enough.
The rest of this section contains various a list of books, links and other resources that might be helpful (but please please keep in mind that in context of RE the most important thing is almost always actually applying the knowledge and almost never just reading about it).
Let's start with books:
• Reverse Engineering for Beginners (2017) by Dennis Yurichev (CC BY-SA 4.0, so yes, it's free and open)
• Practical Malware Analysis (2012) by Michael Sikorski and Andrew Honig
• Practical Reverse Engineering (2014) by Bruce Dang, Alexandre Gazet, Elias Bachaalany, Sebastien Josse
• [Do check out the comment section for other recommendations.]
There are of course more books on the topic, some of which I learnt from, but time has passed and things have changed, so while the books still contain valuable information some of it might be outdated or targeting deprecated tools and environments/architectures. Nonetheless I'll list a couple here just in case someone interested in historic RE stumbles upon this post:
• Hacker Disassembling Uncovered (2003) by Kris Kaspersky (note: first edition of this book was made available for free by the author, however the links no longer work)
• Reversing: Secrets of Reverse Engineering (2005) by Eldad Eilam
• [Do check out the comment section for other recommendations.]
Some other resources that you might find useful:
• Tuts 4 You - a large website dedicated to reverse-engineering. I would especially like to point out the Downloads section which, among other things, contains tutorials, papers and CrackMe challenges (you can find the famous crackmes.de archive there too).
• /r/ReverseEngineering - reddit has a well maintained section with news from the RE industry.
• Reverse Engineering at StackExchange - in case you want to skim through commonly asked questions or ask your own.
• PE Format - Windows executable file format - it's pretty useful to be familiar with it when working on this OS.
• Executable and Linkable Format (ELF) - Linux executable file format (see note above).
• Ange Albertini's executable format posters (among many other things) - analyzing Ange's PE and ELF posters greatly simplifies the learning process for these formats.
• [Do check out the comment section for other recommendations.]
I'll add a few more links to my creations, in case someone finds it useful:
• Practical RE tips (1.5h lecture)
• You might also find some reverse-engineering action as part of my weekly livestreams. An archive can be found on my YouTube channel.
Good luck! And most of all, have fun!
Comments:
https://github.com/eteran/edb-debugger
It is a lot easier than gdb.
You haven’t mentioned .NET reversing, but I’ll share the tool which is one-stop-shop for that platform (disasembler, decompiler, debugger, editor and more):
https://github.com/0xd4d/dnSpy
the internet provides one with tons and tons of info about RE, crackmes or CTFs for windows and linux, though tutorials or workarounds on macOS are sparse.
Is RE on macOS so different from windows/linux? Does one have to consult different literature and if so, is there any you could recommend?
By the way @Gynvael: a really nice introduction on how to get startet
// pruvnic
A great question, though I'm sadly not a good person to answer it, as my experience with OSX is both limited and outdated (my last RE attempts on OSX were around this post - http://gynvael.coldwind.pl/?id=169).
The main difference are around these three parts:
1. The dominant programming language on that platform, which is Objective C - it's different than C++ under a disassembler and one has to get used to it.
2. The executable format is different as well (Mach-O), with each file being usually an archive of several executables for various platforms (x86-32, x86-64, sometimes even PPC).
3. The operating system APIs and libraries are unique to that platform (excluding the Unix part of the system of course). One book I had about this part was "Mac OS X Internals: A Systems Approach" by Amit Singh, but it might be somewhat dated now.
I hope that my readers would be able to provide a better answer to your question.
RE is a tool, which is useful in some areas and absolutely irrelevant in others.
Personally I've used RE technique in these areas:
- binary analysis for various purposes (e.g. malware, interoperability, patches, etc)
- low-level security (e.g. analysis of attack surface of a given application, or just plain old bug hunting)
- debugging (i.e. when programming)
It's probably useful in a couple of other areas, but that's about it :)
I am a High School student from Texas and I have been doing per say,
easier 'hacking' type things, but reversing has always been really difficult
me and finding your channel and blog, you as a great teacher helps me out
more than you can ever imagine. Again, thank you Gynvael.
Great post, I really enjoyed reading it.
I found your site via youtube channel and have to say I loved the videos on ASM. They are probably THE BEST I have ever seen in Polish language. I have attempted couple of times to get into RE but due to my limited time I was never able to dive deeper into it. This time I'm going to try harder and it is thanks to You!
Kindest Regards,
Mick
For learning how debuggers work I'd recommend a serious of blog posts starting with this one: https://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1
https://ghidra-sre.org/
https://github.com/NationalSecurityAgency/ghidra
Check out https://www.reversinghero.com. It is a Reverse Engineering challenge made of 15 levels (x64 on Linux).
Add a comment: